 Back
BackCh. 26 Analysis of Variance (ANOVA): Comparing Several Groups in Business Statistics
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Chapter 26: Analysis of Variance (ANOVA)
26.1 Comparing Several Groups
Analysis of Variance (ANOVA) is a statistical method used to compare the means of three or more groups to determine if at least one group mean is significantly different from the others. In business statistics, ANOVA is often applied using regression models with dummy variables to analyze experimental or observational data involving categorical explanatory variables.
Comparing Groups: The Wheat Variety Example
Scenario: Five wheat varieties (Endurance, Hatcher, NuHills, RonL, Ripper) are tested for yield (bushels per acre) in a balanced experiment (equal observations per group).
Purpose: To determine if yield differences are due to variety, temperature, or random chance.
Steps in ANOVA:
Plot the data to visualize group differences.
Propose a regression model with dummy variables for each group.
Check model assumptions (independence, equal variances, normality).
Test hypotheses and draw conclusions.
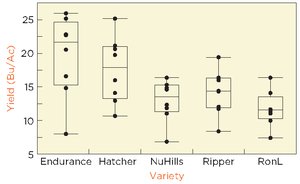
Descriptive Statistics for Each Variety
The table below summarizes the mean and standard deviation for each wheat variety:
Variety | Mean | Std Dev |
|---|---|---|
Endurance | ||
Hatcher | ||
NuHills | ||
Ripper | ||
RonL |
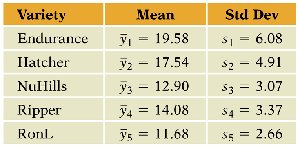
Relating the t-Test to Regression
To compare Endurance to all other varieties, a two-sample t-test can be used if variances are similar. The t-test result can be interpreted using regression with a dummy variable for Endurance:
Term | Estimate | Std Error | t-Statistic | p-Value |
|---|---|---|---|---|
Difference | 5.53 | 1.79 | 3.10 | 0.0037 |

The regression model with a dummy variable for Endurance is:
If : bushels/acre (average for other varieties)
If : bushels/acre (average for Endurance)
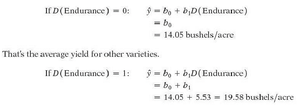
Regression with Multiple Dummy Variables
To compare all varieties, use J-1 dummy variables (for J groups). RonL is the baseline (all dummies = 0). The regression model is:
The intercept is the mean for RonL; each slope is the difference between variety and RonL.
Term | Estimate | Std Error | t-Statistic | p-Value |
|---|---|---|---|---|
Intercept | 11.68 | 1.49 | 7.84 | <.0001 |
D(Endurance) | 7.90 | 2.11 | 3.75 | 0.0006 |
D(Hatcher) | 5.86 | 2.11 | 2.78 | 0.0087 |
D(NuHills) | 1.22 | 2.11 | 0.58 | 0.5682 |
D(Ripper) | 2.40 | 2.11 | 1.14 | 0.2633 |
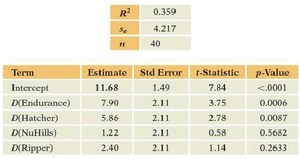
The fitted value for Hatcher is bushels/acre.
ANOVA Regression Model in Population Terms
The ANOVA regression model can be written as:
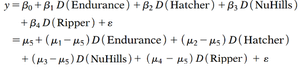
One-Way ANOVA Model and Assumptions
One-way ANOVA compares the means of groups defined by a single categorical variable. The model is:
Assumptions: errors are independent, have equal variances, and are normally distributed.
26.2 Inference in ANOVA Regression Models
Before conducting inference, check the following conditions:
Independence: Satisfied if data are from a randomized experiment.
Equal variances: Check if group IQRs are within a factor of 3 to 1.
Normality: Assess with residual plots and normal quantile plots.
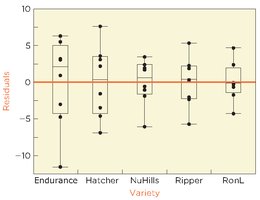
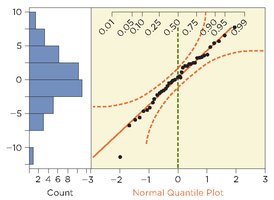
F-Test for the Difference Among Means
The F-test evaluates the null hypothesis . The ANOVA table summarizes the test:
Source | df | Sum of Squares | Mean Square | F | p-Value |
|---|---|---|---|---|---|
Regression | 4 | 54.884 | 13.72 | 3.500 | 0.0090 |
Residual | 35 | 137.322 | 3.923 | ||
Total | 39 | 192.206 |

If the p-value is less than 0.05, reject and conclude that not all means are equal.
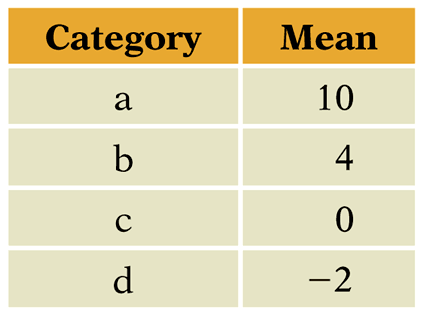
Understanding the F-Test
The F-test compares the variance between group means to the variance within groups. If between-group variance is much larger, group means are likely different. Otherwise, differences may be due to random variation.
Category | Mean |
|---|---|
a | 10 |
b | 4 |
c | 0 |
d | -2 |
26.3 Multiple Comparisons
When comparing multiple groups, the risk of Type I error increases. Multiple comparison procedures adjust for this risk.
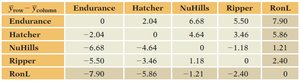
Pairwise Differences Table
Endurance | Hatcher | NuHills | Ripper | RonL | |
|---|---|---|---|---|---|
Endurance | 0 | 2.04 | 6.68 | 5.50 | 7.90 |
Hatcher | -2.04 | 0 | 4.64 | 3.46 | 5.86 |
NuHills | -6.68 | -4.64 | 0 | 1.18 | 1.21 |
Ripper | -5.50 | -3.46 | 1.18 | 0 | 2.40 |
RonL | -7.90 | -5.86 | -1.21 | -2.40 | 0 |
Tukey Confidence Intervals
Controls the overall Type I error rate at 5% for all pairwise comparisons.
Uses a larger critical value than the t-interval, based on the number of groups.
Example: For Endurance vs. Hatcher, the 95% Tukey interval is bushels/acre. Since this interval includes 0, the difference is not significant.
Any difference must exceed 6.07 bushels/acre to be significant at the 5% level.
Bonferroni Confidence Intervals
Adjusts the significance level for multiple comparisons: for intervals.
For 10 comparisons, becomes ; the t-critical value increases, making intervals wider and more conservative.
26.4 Groups of Different Size
When group sizes are unequal (unbalanced data), the standard errors for pairwise comparisons differ. The estimated standard error for comparing two group means is calculated using the sample sizes for each group.
Additional info: The formula for the standard error in the unbalanced case is:
where is the pooled standard deviation, and , are the sample sizes for the two groups.
