 Back
BackMolecular Basis of Inheritance and Gene Expression: DNA Replication, Repair, and Protein Synthesis
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Chapter 16: The Molecular Basis of Inheritance – DNA Replication and Repair
Historical Experiments in DNA Biology
Understanding DNA replication and its role as genetic material was established through several key experiments:
Meselson-Stahl Experiment: Demonstrated that DNA replication is semi-conservative, meaning each new DNA molecule consists of one parental and one newly synthesized strand.
Hershey and Chase: Showed that DNA, not protein, is the genetic material transferred by viruses into bacteria.
Watson, Crick, and Franklin: Discovered the double helix structure of DNA, with antiparallel strands.
Chargaff's Rules: Established that the amount of adenine equals thymine, and guanine equals cytosine in DNA.
Introduction to DNA Replication
DNA replication is the process by which a cell copies its DNA, ensuring genetic information is passed to daughter cells. The two strands of DNA run antiparallel and serve as templates for new strand synthesis. Multiple proteins and enzymes coordinate this process.
Replication is fundamentally similar in prokaryotes and eukaryotes.
Each parental strand serves as a template for a new complementary strand.
Components of DNA Replication
DNA replication requires several key enzymes and proteins:
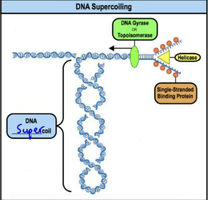
Topoisomerase (DNA Gyrase): Relieves supercoiling ahead of the replication fork.
Helicase: Unwinds the DNA double helix at the replication fork.
Single-Stranded Binding Proteins (SSBs): Stabilize unwound DNA strands and prevent reannealing.
Primase: Synthesizes short RNA primers to provide starting points for DNA polymerases.
DNA Polymerase III: Main enzyme for synthesizing new DNA in prokaryotes.
DNA Polymerase I: Replaces RNA primers with DNA.
DNA Ligase: Joins Okazaki fragments on the lagging strand to create a continuous DNA strand.
Origin of Replication and Replication Forks
DNA replication begins at specific sequences called origins of replication (ORI). Prokaryotes typically have one ORI, while eukaryotes have multiple. Proteins bind to the ORI, separating the DNA strands and forming replication forks—Y-shaped regions where DNA is unwound and synthesis occurs bidirectionally.
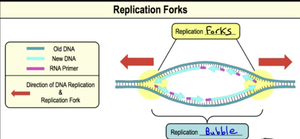
Unwinding the DNA: Topoisomerase, Helicase, and SSBs
Several proteins facilitate the unwinding of DNA:
Topoisomerase: Cuts and rejoins DNA to relieve supercoiling.
Helicase: Breaks hydrogen bonds to separate DNA strands.
SSBs: Bind to single-stranded DNA to prevent reannealing and degradation.
Leading and Lagging DNA Strands
At each replication fork, two types of new DNA strands are synthesized:
Leading Strand: Synthesized continuously in the same direction as the replication fork movement; requires only one RNA primer.
Lagging Strand: Synthesized discontinuously in short fragments (Okazaki fragments) in the opposite direction; each fragment requires a new RNA primer and is later joined by DNA ligase.
DNA synthesis always proceeds in the 5' to 3' direction.
DNA Polymerases
DNA polymerases are the main enzymes responsible for new DNA synthesis. They require:
A template strand (parental DNA)
A primer (short RNA segment synthesized by primase)
DNA polymerase III (prokaryotes) elongates the new strand, while DNA polymerase I replaces RNA primers with DNA.
DNA Repair and Proofreading
DNA replication is not error-free. DNA polymerases have proofreading abilities, reducing the error rate from 1 in 100,000 to 1 in 10 billion base pairs. Additional repair enzymes correct errors missed during replication. Unrepaired errors can lead to mutations and diseases such as cancer.
Telomeres and Telomerase
Telomeres are repetitive, non-coding DNA sequences at the ends of eukaryotic chromosomes. They protect chromosome ends but shorten with each cell division, contributing to cellular aging. Telomerase is an enzyme that extends telomeres, active in germ cells and cancer cells, allowing continuous division.
Chromosome Structure and Organization
Nucleosomes: DNA wraps around histone proteins, forming bead-like structures.
Chromatin: Nucleosomes coil to form relaxed chromatin during interphase.
Chromosome Condensation: Chromatin condenses into visible chromosomes during mitosis for even DNA segregation.
Chapter 17: Gene Expression – From Gene to Protein
Introduction to Transcription
Transcription is the process of synthesizing RNA from a DNA template within a gene. Genes are DNA sequences that encode functional products (RNA or protein). Transcription begins at a promoter and ends at a terminator sequence.
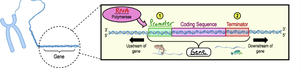
Overview and Steps of Transcription
Transcription involves three main steps:
Initiation: RNA polymerase binds to the promoter and unwinds DNA. In eukaryotes, transcription factors are also required.
Elongation: RNA polymerase synthesizes RNA in the 5' to 3' direction, pairing RNA nucleotides with the DNA template strand.
Termination: Transcription ends at the terminator sequence. In eukaryotes, the resulting pre-mRNA undergoes further processing.
RNA polymerase does not require a primer and cannot proofread as efficiently as DNA polymerase.
Eukaryotic RNA Processing and Splicing
In eukaryotes, pre-mRNA undergoes several modifications before translation:
5' Cap: Added to the 5' end for protection and ribosome binding.
Poly-A Tail: Added to the 3' end for stability and export from the nucleus.
Splicing: Removal of non-coding introns and joining of coding exons by the spliceosome.
Alternative Splicing: Allows for different proteins to be produced from the same gene.
Types of RNA
Messenger RNA (mRNA): Carries genetic information from DNA to ribosomes; contains codons specifying amino acids.
Ribosomal RNA (rRNA): Structural and catalytic component of ribosomes.
Transfer RNA (tRNA): Brings amino acids to the ribosome; contains anticodons complementary to mRNA codons.
Introduction to Translation
Translation is the process of synthesizing proteins using the sequence encoded in mRNA. Ribosomes facilitate the assembly of amino acids into polypeptides, with tRNAs delivering the correct amino acids based on codon-anticodon pairing.
Translation occurs in the cytoplasm.
Peptide bonds form between amino acids, creating a polypeptide chain.
Central Dogma of Molecular Biology
The central dogma describes the flow of genetic information: DNA → RNA → Protein. Transcription produces RNA from DNA, and translation synthesizes proteins from mRNA. In prokaryotes, these processes are coupled; in eukaryotes, mRNA is processed before translation.
Genetic Code
The genetic code is a set of rules by which nucleotide sequences in mRNA are translated into amino acid sequences in proteins. Each codon (three nucleotides) specifies one amino acid. The code is nearly universal and includes start (AUG, methionine) and stop codons.
Transcription: DNA sequence → mRNA sequence
Translation: mRNA codons → amino acids
Post-Translational Modification
After translation, proteins may undergo covalent modifications that regulate their function, location, or stability. Common types include:
Methylation: Addition of a methyl group, affecting interactions.
Acetylation: Addition of an acetyl group, influencing gene expression and protein stability.
Ubiquitination: Attachment of ubiquitin, marking proteins for degradation.
Phosphorylation: Addition of a phosphate group, regulating enzyme activity.
Glycosylation: Addition of carbohydrates to proteins.
Other modifications: Hydroxylation, lipidation, disulfide bond formation, sulfonation.
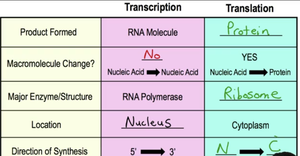
Summary Table: Transcription vs. Translation
Transcription | Translation | |
|---|---|---|
Product Formed | RNA Molecule | Protein |
Macromolecule Change? | No (Nucleic Acid → Nucleic Acid) | Yes (Nucleic Acid → Protein) |
Major Enzyme/Structure | RNA Polymerase | Ribosome |
Location | Nucleus | Cytoplasm |
Direction of Synthesis | 5' → 3' | N-terminus → C-terminus |
Key Equations and Concepts
DNA Synthesis Direction:
Base Pairing: , (in DNA); in RNA
Central Dogma:
