 Back
BackChapter 1: Data Collection – Foundations of Statistical Practice
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Section 1.1: Introduction to the Practice of Statistics
Definition and Scope of Statistics
Statistics is the science of collecting, organizing, summarizing, and analyzing information to draw conclusions or answer questions. It also involves providing a measure of confidence in any conclusions. The information used in statistics is called data, which describes characteristics of individuals and exhibits variability.
Statistics: The science of data analysis for decision-making.
Data: Facts or propositions used to draw conclusions or make decisions.
Variability: The tendency of data to differ among individuals or over time.
Example: Data such as heights, hair colors, or hours of sleep vary among individuals and over time.
The Process of Statistics
The process of statistics involves four main steps:
Identify the research objective: Clearly state the question and population of interest.
Collect the data: Gather data relevant to the research objective, often from a sample.
Describe the data: Use descriptive statistics to summarize and organize the data.
Perform inference: Apply inferential statistics to extend results from the sample to the population and report reliability.

Example: In a study of high school start times and sleep duration, researchers sampled 383 adolescents, summarized their sleep data, and concluded that later start times are associated with longer sleep duration.
Descriptive vs. Inferential Statistics
Descriptive statistics: Organizing and summarizing data using numerical summaries, tables, and graphs.
Inferential statistics: Methods that use sample results to make generalizations about a population and measure reliability.
Parameter: Numerical summary of a population.
Statistic: Numerical summary of a sample.
Section 1.1: Types of Variables
Qualitative vs. Quantitative Variables
Variables are characteristics of individuals in a population. They can be classified as:
Qualitative (Categorical) Variables: Classify individuals based on attributes or characteristics (e.g., gender, education level).
Quantitative Variables: Provide numerical measures of individuals. Values can be added or subtracted meaningfully (e.g., height, temperature).
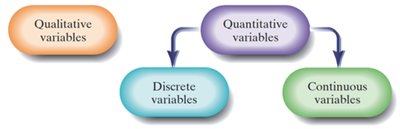
Example: Education level is qualitative; daily intake of whole grains is quantitative.
Discrete vs. Continuous Variables
Discrete Variable: Quantitative variable with a finite or countable number of possible values (e.g., number of vending machines).
Continuous Variable: Quantitative variable with an infinite number of possible values, not countable (e.g., height, gas mileage).
Example: Number of children is discrete; grade earned as a percentage is continuous.
Levels of Measurement
Nominal: Values name, label, or categorize without a ranked order (e.g., gender).
Ordinal: Values can be ranked or ordered (e.g., income status: low, middle, high).
Interval: Differences between values have meaning; zero does not indicate absence (e.g., temperature in Celsius).
Ratio: Ratios of values have meaning; zero indicates absence (e.g., income, number of children).
Section 1.2: Observational Studies Versus Designed Experiments
Observational Studies vs. Experiments
Observational Study: Measures the value of the response variable without influencing variables. Can show association, not causation.
Designed Experiment: Researcher assigns treatments to groups, manipulates explanatory variables, and controls other variables to determine causation.
Confounding: When effects of two or more explanatory variables are not separated.
Lurking Variable: An unconsidered variable that affects the response variable.
Types of Observational Studies
Cross-sectional: Collects information at a specific point in time.
Case-control: Retrospective; compares individuals with and without a characteristic.
Cohort: Prospective; follows a group over time to record characteristics.
Section 1.3 & 1.4: Sampling Methods
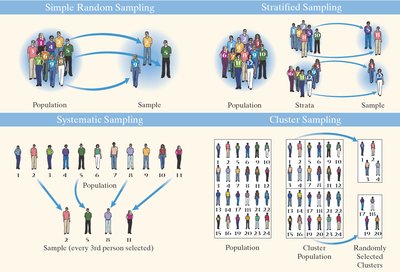
Simple Random Sampling
Every possible sample of size n from a population of size N has an equally likely chance of being selected.
Number all individuals in the population.
Randomly select n numbers using a random number generator or table.
Other Effective Sampling Methods
Stratified Sampling: Divide population into homogeneous groups (strata), then randomly sample from each stratum.
Systematic Sampling: Select every kth individual from a list, starting at a random point.
Cluster Sampling: Divide population into groups (clusters), randomly select some clusters, and include all individuals from those clusters.
Convenience Sampling: Select individuals easily obtained; not based on randomness and often leads to bias.
Section 1.5: Bias in Sampling
Sources of Bias
Sampling Bias: Sampling method favors one part of the population.
Nonresponse Bias: Individuals who do not respond differ from those who do.
Response Bias: Survey answers do not reflect true feelings due to interviewer error, misrepresented answers, or question wording.
Data-entry Error: Mistakes in recording or entering data.
Nonsampling Error: Errors from bias or data-entry mistakes, present even in a census.
Sampling Error: Error from using a sample to estimate population information.
Section 1.6: The Design of Experiments
Characteristics of an Experiment
Experiment: Controlled study to determine the effect of explanatory variables (factors) on a response variable.
Treatment: Any combination of values of the factors.
Experimental Unit: The subject or object receiving the treatment.
Control Group: Baseline group for comparison, may receive a placebo.
Placebo Effect: Improvement due to the belief in treatment, not the treatment itself.
Blinding: Single-blind (subject unaware of treatment), double-blind (both subject and researcher unaware).
Steps in Designing an Experiment
Identify the problem to be solved.
Determine the factors that affect the response variable.
Determine the number of experimental units.
Determine the level of each factor (control or randomize).
Conduct the experiment.
Replication: Apply each treatment to multiple units.
Collect and process data.
Test the claim using inferential statistics.


Completely Randomized Design
Each experimental unit is randomly assigned to a treatment group.
Ensures that treatment groups are similar except for the treatment applied.
Matched-Pairs Design
Experimental units are paired based on similarity; each pair receives different treatments. Used when only two levels of treatment exist.
Examples: Same person before and after treatment, twins, or matched subjects.
Additional info: These foundational concepts are essential for understanding how to collect, summarize, and analyze data in statistics, and for designing valid experiments and surveys.
