 Back
BackChapter 18: Inferences About Means – The t-Distribution and Small Sample Inference
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Inferences About Means
Introduction to Inference for Means
Statistical inference about population means is a fundamental topic in statistics. When the population standard deviation (σ) is unknown and the sample size is small, we must use special methods to account for extra uncertainty. This chapter focuses on the use of the Student's t-distribution for constructing confidence intervals and hypothesis tests about means under these conditions.
The Central Limit Theorem (CLT) Revisited
Sampling Distribution of the Mean
Central Limit Theorem (CLT): For sufficiently large sample sizes, the sampling distribution of the sample mean is approximately normal, regardless of the population's distribution.
Mean and Standard Deviation: The sampling distribution has mean equal to the population mean (μ) and standard deviation equal to the population standard deviation divided by the square root of the sample size:
When σ is unknown, we estimate it with the sample standard deviation (s), leading to the standard error:
Student's t-Distribution
Origin and Properties
William S. Gosset (pseudonym "Student") developed the t-distribution while working at Guinness Brewery.
The t-distribution is used when the population standard deviation is unknown and the sample size is small.
The t-distribution forms a family of distributions indexed by degrees of freedom (df), typically df = n - 1.
Compared to the standard normal (z) distribution, the t-distribution is flatter and has heavier tails, reflecting greater uncertainty.


As the sample size increases (df increases), the t-distribution approaches the standard normal distribution.
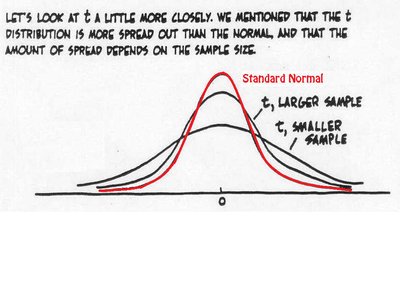

Key Characteristics of the t-Distribution
Unimodal and symmetric about zero.
Mean of zero.
Heavier tails than the normal distribution (more probability in the tails).
Shape depends on degrees of freedom (df = n - 1).
As df → ∞, t-distribution becomes the standard normal distribution.
Using the t-Distribution for Inference
t-Distribution Tables and Critical Values
Tables provide critical values for selected confidence levels and degrees of freedom.
For large df, t-values approach z-values.
Common tail probabilities: 0.10, 0.05, 0.025, 0.01, 0.005.
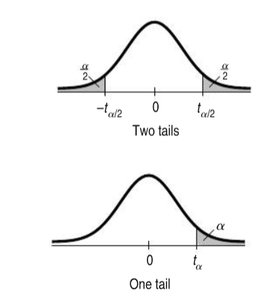
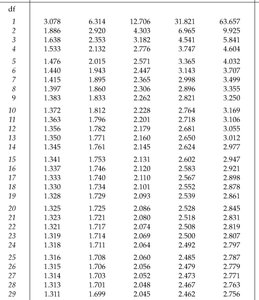
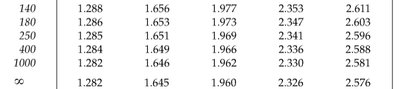
For degrees of freedom not listed, approximate by using the next lower df or use statistical software.
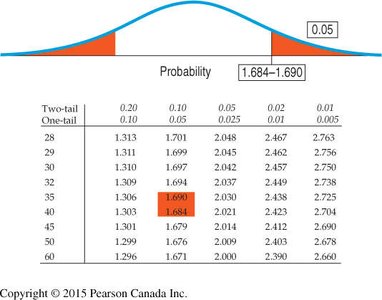
Degrees of Freedom and Sample Standard Deviation
Sample standard deviation is calculated using n - 1 in the denominator to correct for bias when estimating from the sample mean:
This adjustment is called the degrees of freedom correction.
Confidence Intervals for the Mean (t-Interval)
Constructing a t-Interval
When the sample size is small (n < 60) and σ is unknown, the confidence interval for the population mean is:
where and is the critical value from the t-distribution with df = n - 1.
t-intervals are wider than z-intervals, reflecting extra uncertainty from estimating σ.
One-Sample t-Test for the Mean
Hypothesis Testing Procedure
Used when testing hypotheses about a population mean with unknown σ and small n.
Test statistic:
Compare the calculated t to the critical value from the t-table, or use the p-value approach.
Types of tests: lower-tailed, upper-tailed, and two-tailed.
Assumptions and Conditions for t-Methods
Independence Assumption: Data values must be independent.
Randomization Condition: Data should come from a random sample or randomized experiment.
10% Condition: Sample size should be less than 10% of the population when sampling without replacement.
Normal Population Assumption: The population should be approximately normal, or the sample size should be large enough for the CLT to apply.
Nearly Normal Condition: For small samples, check for unimodality and symmetry using histograms, boxplots, or normal probability plots.
Examples
Example 1: Humerus Bones
Archaeologists test whether unearthed bones belong to species A (mean ratio = 8.5).
Sample: n = 41, mean = 9.258, s = 1.204, SE = 0.188.
Hypotheses: ,
Test statistic:
p-value < 0.01, so reject ; bones are not from species A.
99% CI:
Assumptions checked: Histogram and boxplot show unimodal, symmetric data with two outliers; normality test p-value > 0.05.
Example 2: Apple Juice Fill
Quality control manager tests if bottles are under-filled (target = 64.05 oz).
Sample: n = 22, mean = 64.0073, s = 0.0446, SE = 0.0095.
Hypotheses: ,
Test statistic:
p-value < 0.01, so reject ; mean fill is lower than target.
99% upper bound: 64.0312 oz.
Assumptions: Boxplot is symmetric, data are normal, random sample, n < 10% of population.
Sample Size Determination
Calculating Required Sample Size
To estimate the mean within a margin of error (ME) at a given confidence level, solve:
Use s from a pilot study if σ is unknown.
For the apple juice example, to estimate the mean within 0.01 oz at 99% confidence (z* = 2.576, s = 0.0446):
Common Pitfalls and Best Practices
Do not confuse means and proportions.
Check for multimodality and skewness; t-methods are robust to mild deviations from normality, but not to severe ones.
Beware of outliers and bias; always report on outliers and ensure random sampling.
Interpret confidence intervals correctly: they refer to the population mean, not individual values.
Choose the alternative hypothesis before seeing the data.
Summary of Key Formulas
Standard Error:
Confidence Interval:
t-Test Statistic:
Sample Size:
What Have We Learned?
How to use the t-distribution for inference about means when σ is unknown and n is small.
How to construct confidence intervals and perform hypothesis tests using the t-distribution.
The importance of checking assumptions and conditions before applying t-methods.
How to determine the required sample size for a desired margin of error.
