 Back
BackChapter 23: Inferences for Regression – Study Notes
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Inferences for Regression
Introduction to Regression Analysis
Regression analysis is a statistical method used to model and analyze the relationship between a dependent (response) variable and one or more independent (predictor) variables. The goal is to predict or explain the dependent variable using the independent variable(s).
Dependent variable (y): The outcome or variable to be predicted.
Independent variable (x): The variable used to predict y.
The equation for the line of best fit (simple linear regression):
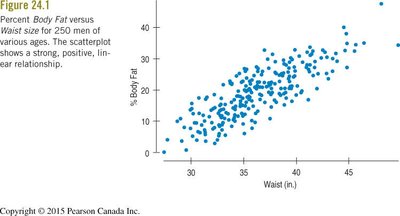
Example: Predicting percent body fat from waist size in men.
The Population Regression Model
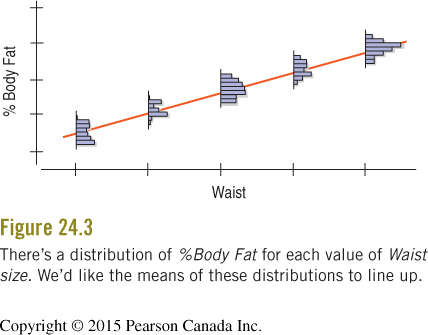
We use regression to make inferences about the population, not just the sample. The idealized regression line for the population is written as:
For individual data points, we include random error:
Where is the residual error, assumed to be random and normally distributed.
Key Terms:
Intercept (): Expected value of y when x = 0.
Slope (): Expected change in y for a one-unit increase in x.
Residual (): The difference between observed and predicted y.
Assumptions and Conditions for Regression Inference
1. Linearity Assumption
The relationship between x and y must be linear. This is checked using a scatterplot of the data (Straight Enough Condition).
If the scatterplot is not linear, consider transforming the data.
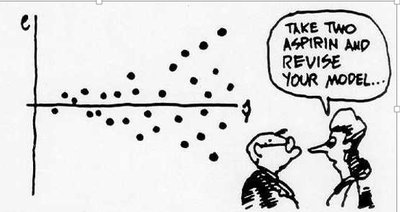
2. Independence Assumption
The observations must be independent. This is often ensured by random sampling (Randomization Condition). Independence can also be checked by plotting residuals versus the x-variable; the residuals should appear randomly scattered.
3. Equal Variance Assumption (Homoscedasticity)
The spread of the residuals should be roughly constant for all values of x (Does the Plot Thicken? Condition). This is checked using a residuals vs fits plot.
If the spread increases or decreases with x, the assumption is violated.
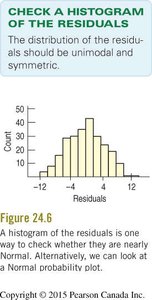
4. Normal Population Assumption
The residuals should be nearly normally distributed (Nearly Normal Condition). This is checked using a histogram or a normal probability plot of the residuals. Outliers should also be checked.
Summary of Assumptions
Linearity: Relationship between x and y is linear.
Independence: Observations are independent.
Equal Variance: Residuals have constant variance.
Normality: Residuals are normally distributed.
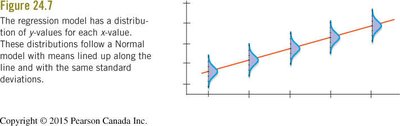
Order of Conducting a Simple Regression Analysis
Check linearity with a scatterplot.
Fit the regression model and examine residuals vs fits plot for patterns.
Check the histogram and normal probability plot of residuals for normality.
If data are time series, plot residuals vs time to check for independence.
Intuition About Regression Inference
Factors Affecting the Standard Error of the Slope
Spread around the line (se): Less scatter means more consistent slope estimates.
Spread of x values (sx): Greater spread in x gives more stable regression estimates.
Sample size (n): Larger sample size gives more consistent estimates.
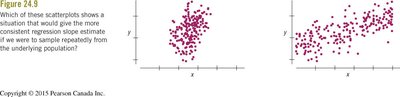
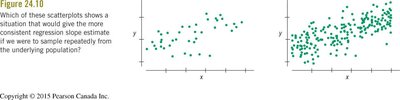
Standard Error of the Slope
The standard error of the regression slope is calculated as:
= residual standard deviation
= standard deviation of x-values
= sample size
Inference for Regression Slope
Hypothesis Test for Slope
Null hypothesis: (no relationship between x and y)
Alternative hypothesis: (x and y are related)
Test statistic: with degrees of freedom
Confidence interval for slope:
Example: Testing the Relationship Between % Body Fat and Waist Size
Term | Coef | SE Coef | T-Value | P-Value |
|---|---|---|---|---|
Constant | -62.6 | 10.2 | -6.16 | 0.000 |
Waist | 2.222 | 0.273 | 8.14 | 0.000 |
Test statistic:
P-value < 0.05, so we reject and conclude a significant linear relationship exists.
Confidence Interval for the Slope
For 95% confidence and 18 degrees of freedom:
Interpretation: For every 1 inch increase in waist size, percent body fat increases by between 1.648% and 2.796%.
Estimation and Prediction Using the Regression Model
Confidence Interval for Mean Response
To estimate the mean value of y for a given x ():
Where is the standard error for the mean response at .
Prediction Interval for a New Observation
To predict the value of y for a new individual at :
Where includes an extra term for the variability of individual observations.
Comparison of Intervals
Confidence Interval (CI): For the mean response at a given x; narrower interval.
Prediction Interval (PI): For a single new observation at a given x; wider interval due to extra uncertainty.
Common Pitfalls in Regression Inference
Do not fit a linear model to non-linear data.
Check for non-constant variance (plot thickening).
Be cautious with extrapolation (predicting outside the range of data).
Watch for outliers and high-influence points.
Ensure residuals are nearly normal.
Use two-tailed tests unless a one-tailed test is justified.
Summary of Key Skills
Check all regression assumptions before making inferences.
Interpret regression output, including slope, intercept, standard errors, t-values, and p-values.
Construct and interpret confidence and prediction intervals.
Understand the difference between inference for the mean response and for individual predictions.
