Back
BackChapter 3: Numerical Descriptive Measures in Statistics
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
3.1 Measures of Central Tendency for Ungrouped Data
Definition and Importance
Measures of central tendency are statistical values that describe the center or typical value of a data set. The three main measures are the mean, median, and mode. These measures help summarize and understand large data sets by identifying a representative value.

Mean
The mean (or average) is calculated by dividing the sum of all values by the number of values in the data set. It is sensitive to every value, including outliers.
Population Mean:
Sample Mean:
Where is the sum of all values, is the population size, is the sample size, is the population mean, and is the sample mean.
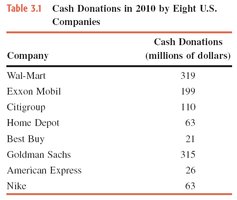
Example: Table 3.1 shows cash donations by eight U.S. companies in 2010. The mean donation is calculated by summing all donations and dividing by 8.
Median
The median is the value of the middle term in a data set arranged in increasing order. If the number of values is odd, the median is the middle value; if even, it is the average of the two middle values.
Step 1: Rank the data in increasing order.
Step 2: Identify the middle value(s).
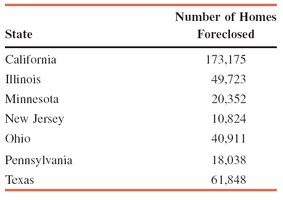
Example: Table 3.2 lists the number of homes foreclosed in seven states in 2010. The median is the fourth value when the data is ordered.

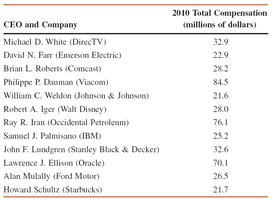
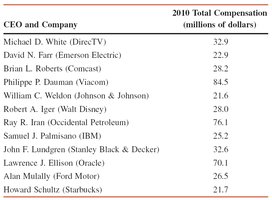
Example: Table 3.3 shows the total compensation of 12 highest-paid CEOs in 2010. The median is the average of the 6th and 7th values in the ordered list.

Mode
The mode is the value that occurs most frequently in a data set. A data set may have no mode, one mode (unimodal), two modes (bimodal), or more than two modes (multimodal). The mode can be used for both quantitative and qualitative data.
Unimodal: One mode
Bimodal: Two modes
Multimodal: More than two modes
Relationships Among the Mean, Median, and Mode
The relationship among mean, median, and mode depends on the shape of the data distribution:
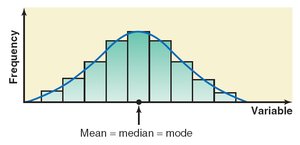
Symmetric Distribution: Mean = Median = Mode (center of the distribution)
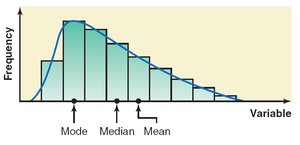
Right-Skewed Distribution: Mean > Median > Mode (mean is pulled right by outliers)
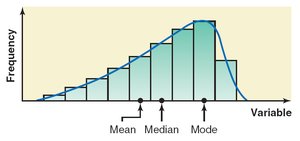
Left-Skewed Distribution: Mean < Median < Mode (mean is pulled left by outliers)
3.2 Measures of Dispersion for Ungrouped Data
Definition and Importance
Measures of dispersion describe the spread or variability of a data set. Common measures include the range, variance, and standard deviation. These measures help assess the reliability and consistency of the data.

Range
The range is the difference between the largest and smallest values in a data set.
Formula:
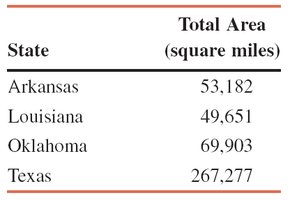
Example: Table 3.4 shows the total area of four states. The range is calculated as the difference between the largest and smallest area values.
Variance and Standard Deviation
The variance measures the average squared deviation from the mean. The standard deviation is the positive square root of the variance and is the most commonly used measure of dispersion.
Population Variance:
Sample Variance:
Population Standard Deviation:
Sample Standard Deviation:
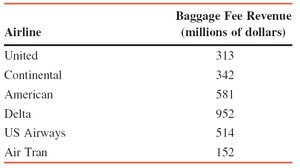
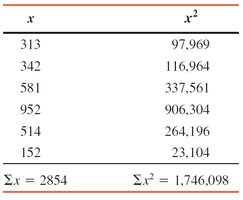
Example: Table shows baggage fee revenues for six airlines. The variance and standard deviation are calculated using the sum of values and the sum of squared values.
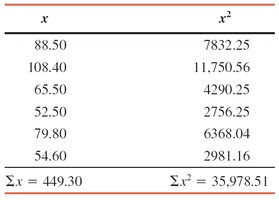
Example: Table shows earnings for six employees. The variance and standard deviation are calculated similarly.
3.3 Mean, Variance, and Standard Deviation for Grouped Data
Mean for Grouped Data
For grouped data, the mean is calculated using the midpoints of the classes and their frequencies.
Population Mean:
Sample Mean:
Where is the class midpoint and is the class frequency.
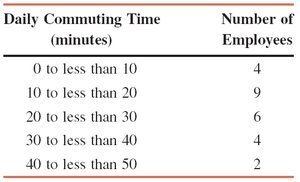
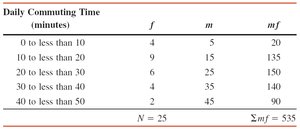
Example: Table shows the frequency distribution of daily commuting times for 25 employees. The mean is calculated using the midpoints and frequencies.
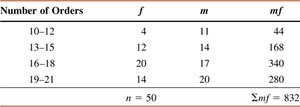
Example: Table shows the frequency distribution of number of orders received each day. The mean is calculated similarly.

Variance and Standard Deviation for Grouped Data
The formulas for variance and standard deviation for grouped data use the midpoints and frequencies:
Population Variance:
Sample Variance:
Population Standard Deviation:
Sample Standard Deviation:
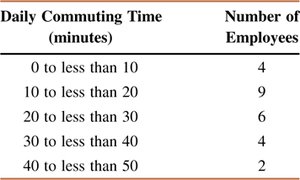
Example: Table shows the frequency distribution of daily commuting times. The variance and standard deviation are calculated using the midpoints and frequencies.

Example: Table shows the frequency distribution of number of orders. The variance and standard deviation are calculated similarly.


Use of Standard Deviation
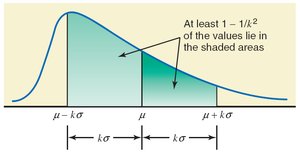
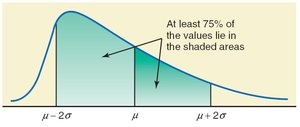
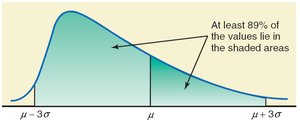
Chebyshev’s Theorem
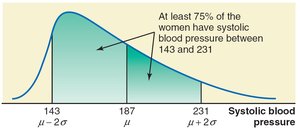
Chebyshev’s theorem states that for any number , at least of the data values lie within standard deviations of the mean, regardless of the data distribution.
Example: For a mean of 187 and standard deviation of 22, at least 75% of values lie between 143 and 231.
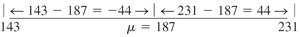
Empirical Rule
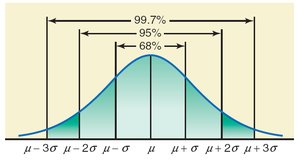
For bell-shaped (normal) distributions:
About 68% of values lie within 1 standard deviation of the mean
About 95% within 2 standard deviations
About 99.7% within 3 standard deviations
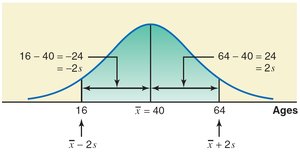
Example: For a mean age of 40 and standard deviation of 12, about 95% of people are between 16 and 64 years old.
Measures of Position
Quartiles and Interquartile Range (IQR)
Quartiles divide a ranked data set into four equal parts. The first quartile (Q1) is the median of the lower half, the second quartile (Q2) is the median, and the third quartile (Q3) is the median of the upper half.
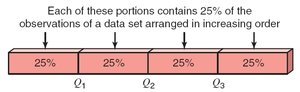
The interquartile range (IQR) is and measures the spread of the middle 50% of the data.
Example: Table 3.3 (CEO compensation) is used to find quartiles and IQR.

Example: Quartile calculation for ages of employees.

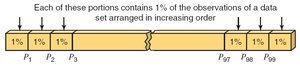
Percentiles and Percentile Rank
Percentiles divide a ranked data set into 100 equal parts. The k-th percentile (Pk) is the value below which k% of the data falls.
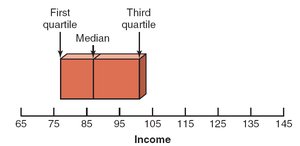
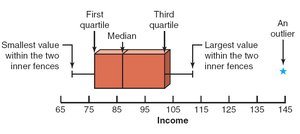
Box-and-Whisker Plot
Definition and Construction
A box-and-whisker plot visually displays the center, spread, and skewness of a data set using the median, quartiles, and extremes (excluding outliers). The box represents the interquartile range, and the whiskers extend to the smallest and largest values within 1.5 IQR of the quartiles.