 Back
BackNumerically Summarizing Data: Measures of Central Tendency, Dispersion, and Position
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Measures of Central Tendency
Arithmetic Mean
The arithmetic mean is a measure of central tendency that represents the average value of a data set. It is calculated by summing all the values and dividing by the number of observations.
Population Mean (μ): Uses all individuals in a population. It is a parameter.
Sample Mean (\(\bar{x}\)): Uses sample data. It is a statistic.
Formulas:
Population Mean:
Sample Mean:
Example: For travel times (in minutes): 23, 36, 23, 18, 5, 26, 43 Population mean: minutes
When to Use: The mean is best used when data are quantitative and the distribution is roughly symmetric.

Median
The median is the value that lies in the middle of the data when arranged in ascending order. It divides the data into two equal halves.
If the number of observations (n) is odd, the median is the middle value: position .
If n is even, the median is the mean of the two middle values: positions and .
When to Use: The median is preferred when the data are skewed left or right, or when outliers are present.
Mode
The mode is the most frequent observation in a data set. A data set can have no mode, one mode, or more than one mode.
If no value repeats, there is no mode.
If one value repeats most often, it is unimodal.
If two or more values tie for most frequent, the data are bimodal or multimodal.
When to Use: The mode is useful for categorical data or when the most common item is of interest.
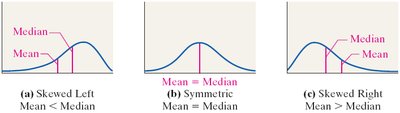
Comparing Mean, Median, and Mode
The relationship between the mean and median helps describe the shape of the distribution:
Distribution Shape | Mean versus Median |
|---|---|
Skewed left | Mean substantially smaller than median |
Symmetric | Mean roughly equal to median |
Skewed right | Mean substantially larger than median |

Measures of Dispersion
Range
The range is the difference between the largest and smallest data values:
Range
Example: For travel times: 43 (max) – 5 (min) = 38 minutes
Standard Deviation and Variance
The standard deviation measures the average distance of data values from the mean. The variance is the square of the standard deviation.
Population Standard Deviation (σ):
Sample Standard Deviation (s):
Population Variance:
Sample Variance:
Degrees of Freedom: For a sample, is used in the denominator to account for the estimation of the mean from the sample data.
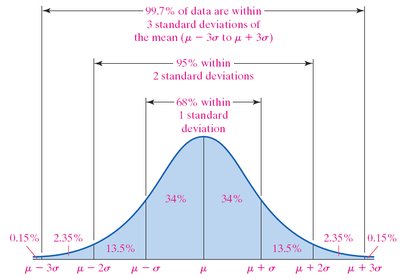
The Empirical Rule
The Empirical Rule applies to bell-shaped (normal) distributions:
About 68% of data lie within 1 standard deviation of the mean.
About 95% within 2 standard deviations.
About 99.7% within 3 standard deviations.
Chebyshev’s Inequality
Chebyshev’s Inequality applies to any data set, regardless of shape. For any , at least of the data lie within standard deviations of the mean.
For , at least 75% of data are within 2 standard deviations.
For , at least 88.9% are within 3 standard deviations.
Measures of Position and Outliers
Z-Scores
A z-score indicates how many standard deviations a value is from the mean:
Population:
Sample:
Z-scores are unitless and allow comparison across different distributions.
Percentiles
The kth percentile () is the value such that percent of the observations are less than or equal to it.

Quartiles
Quartiles divide data into four equal parts:
First quartile (): 25th percentile
Second quartile (): 50th percentile (median)
Third quartile (): 75th percentile

Interquartile Range (IQR)
The interquartile range (IQR) measures the spread of the middle 50% of data:
IQR is resistant to outliers and is preferred for skewed distributions.
Detecting Outliers
Outliers are values that fall outside the typical range of the data. To check for outliers using quartiles:
Lower Fence:
Upper Fence:
Values outside these fences are considered outliers.
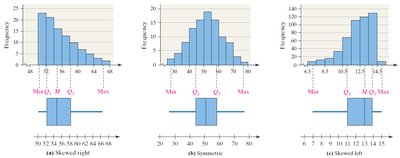
The Five-Number Summary and Boxplots
Five-Number Summary
The five-number summary consists of:
Minimum
First Quartile ()
Median ()
Third Quartile ()
Maximum
Boxplots
A boxplot is a graphical representation of the five-number summary. It displays the distribution's center, spread, and potential outliers.
The box spans from to with a line at the median.
Whiskers extend to the smallest and largest values within the fences.
Outliers are plotted individually.
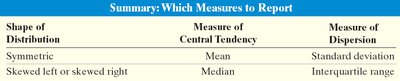
Using Shape to Choose Measures
The choice of central tendency and dispersion measure depends on the distribution's shape:
Shape of Distribution | Measure of Central Tendency | Measure of Dispersion |
|---|---|---|
Symmetric | Mean | Standard deviation |
Skewed left or right | Median | Interquartile range |
Visualizing Distribution Shape
Boxplots and histograms can be used together to describe the shape of a distribution (skewed left, symmetric, skewed right).
Additional info:
Tables and diagrams have been recreated in HTML or referenced with images where directly relevant.
All formulas are provided in LaTeX format for clarity and academic rigor.
