 Back
BackNumerically Summarizing Data: Measures of Central Tendency, Dispersion, and Position
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Numerically Summarizing Data
Overview
Numerical summaries are essential for understanding the characteristics of a data set. The three main characteristics to consider are shape, center, and spread. These summaries allow us to analyze data for patterns and identify unusual values, known as outliers.
Measures of Central Tendency
Definitions and Importance
Measures of central tendency describe the average or typical value in a data set. The three most common measures are the mean, median, and mode. Each measure provides a different perspective on the data's center and may yield different results depending on the data's distribution.
Mean: The arithmetic average, sensitive to extreme values.
Median: The middle value when data are ordered, resistant to outliers.
Mode: The most frequently occurring value(s) in the data set.
Arithmetic Mean
Population Mean (\(\mu\)):
Sample Mean (\(\bar{x}\)):
The mean is often referred to as the "center of gravity" of the data set.
Median
Arrange data in ascending order.
If the number of observations (n) is odd, the median is the middle value.
If n is even, the median is the mean of the two middle values.
Mode
The value(s) that occur most frequently in the data set.
Data can be unimodal, bimodal, or multimodal, or have no mode.
Resistant Statistics
A statistic is resistant if it is not substantially affected by extreme values (outliers).
The median is resistant; the mean is not.
Measures of Dispersion
Definitions and Importance
Dispersion measures the degree to which data values are spread out. Common measures include the range, variance, and standard deviation.
Range
Range (R):
Standard Deviation and Variance
Population Standard Deviation (\(\sigma\)):
Sample Standard Deviation (s):
Variance: The square of the standard deviation. Population variance is , sample variance is .
The standard deviation represents the typical deviation from the mean and is used to judge whether an observation is far from the mean.
The Empirical Rule (for Bell-Shaped Distributions)
Approximately 68% of data lie within 1 standard deviation of the mean.
Approximately 95% within 2 standard deviations.
Approximately 99.7% within 3 standard deviations.
Chebyshev’s Inequality (for Any Distribution)
For any k > 1, at least of the data lie within k standard deviations of the mean.
Measures from Grouped Data
Approximating the Mean and Standard Deviation
When only grouped (frequency) data are available, approximate the mean and standard deviation using class midpoints and frequencies.
Sample Mean (Grouped Data):
Sample Standard Deviation (Grouped Data):
Where is the frequency and is the midpoint of the i-th class.
Weighted Mean
, where is the weight for observation .
Measures of Position and Outliers
Z-Scores
Z-score: (population), (sample)
Indicates how many standard deviations a value is from the mean.
Percentiles and Quartiles
The k-th percentile is the value below which k% of the data fall.
Quartiles divide data into four equal parts: Q1 (25th percentile), Q2 (median, 50th percentile), Q3 (75th percentile).
Interquartile Range (IQR)
Measures the spread of the middle 50% of the data and is resistant to outliers.
Checking for Outliers
Calculate lower fence:
Calculate upper fence:
Values outside these fences are considered outliers.
The Five-Number Summary and Boxplots
Five-Number Summary
Consists of: Minimum, Q1, Median (Q2), Q3, Maximum
Boxplots
A boxplot is a graphical summary of the five-number summary and is useful for visualizing the distribution, spread, and outliers in a data set.
The box spans from Q1 to Q3, with a line at the median.
Whiskers extend to the smallest and largest values within the fences.
Outliers are plotted individually beyond the fences.

Figure: Initial boxplot showing quartiles and fences.

Figure: Boxplot with whiskers extending to non-outlier values.
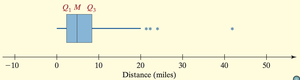
Figure: Final boxplot with outliers marked as points beyond the upper fence.
Comparing Distributions with Boxplots
Side-by-side boxplots allow for comparison between groups, such as ride distances for shared versus non-shared rides. Differences in medians, spread, and presence of outliers can be easily visualized.
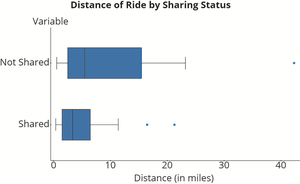
Figure: Side-by-side boxplots comparing ride distances by sharing status.
Summary Table: Measures of Central Tendency and Dispersion
Measure | Definition | Formula | Resistant? |
|---|---|---|---|
Mean | Arithmetic average | No | |
Median | Middle value | -- | Yes |
Mode | Most frequent value | -- | Yes |
Range | Max - Min | No | |
Standard Deviation | Average deviation from mean | No | |
Variance | Square of standard deviation | No | |
IQR | Q3 - Q1 | Yes |
