 Back
BackStatistics: The Art and Science of Learning From Data – Chapter 1 Study Notes
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Statistics: The Art and Science of Learning From Data
Introduction to Statistics
Statistics is the discipline concerned with collecting, analyzing, interpreting, and presenting data. It enables us to answer questions about the world using data from experiments and surveys. The process involves designing studies, analyzing data, and translating findings into knowledge.
Designing Studies: Planning how to collect data, including who to sample and how to conduct experiments or surveys.
Analyzing Data: Summarizing and visualizing data using statistical methods.
Translating Data: Drawing conclusions and assessing confidence in those conclusions.
Example: Evaluating a new teaching method by randomly assigning classrooms, comparing test scores, and determining if differences are statistically significant.
Main Components of Statistics
To answer statistical questions, statistics relies on three main components:
Design: Planning how to obtain data (e.g., random assignment, fair comparison).
Description: Summarizing collected data (e.g., mean, median, mode, standard deviation, charts, graphs).
Inference: Making decisions or predictions based on data (e.g., determining statistical significance, predicting future outcomes).
Sample Versus Population
Definitions and Examples
Understanding the difference between a sample and a population is fundamental in statistics.
Subjects: Entities measured in a study (individuals, schools, countries, etc.).
Population: The entire group of interest.
Sample: A subset of the population, often randomly selected.
Census: When the sample is the entire population.
Parameter: A numerical summary of the population.
Statistic: A numerical summary of the sample.
Example: If we want to know the percentage of UNCW students who visit the library weekly:
Population: All UNCW students
Sample: 500 randomly selected students
Parameter: True percentage of students who visit weekly
Statistic: Percentage of sampled students who visit weekly
Descriptive and Inferential Statistics
Definitions
Statistics is divided into two main branches:
Descriptive Statistics: Methods for summarizing collected data using graphs and numbers (averages, percentages).
Inferential Statistics: Methods for making decisions or predictions about a population based on sample data.
Example: Predicting the average number of cups of coffee consumed by all UNCW coffee drinkers based on a sample.
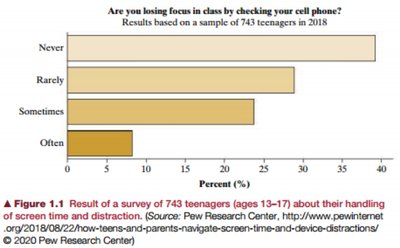
Randomness and Variability
Random Sampling
Random sampling ensures each subject in the population has an equal chance of being selected. This is crucial for making valid inferences about populations.
Randomness: Essential for unbiased experiments and surveys.
Variability: Observations vary within samples and between samples.
Within Sample Variability: Differences among individuals in a sample.
Between Sample Variability: Differences in statistics computed from different samples.
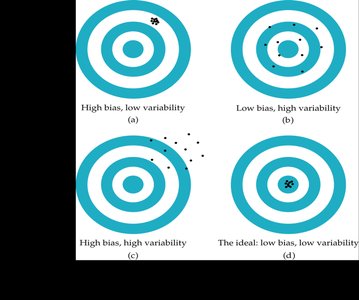
Margin of Error
Definition and Example
The margin of error quantifies how close an estimate is expected to be to the true population parameter.
Definition: The margin of error measures the expected range of error in an estimate.
Example: A margin of error of ±3 percentage points means the true value is likely within 3% of the sample estimate.
Confidence: "Very likely" typically means 95% confidence (see Chapter 8).
Statistical Significance
Definition
Statistical significance indicates that observed differences between groups are unlikely to be due to random sample-to-sample variability.
Significance: The difference is larger than expected by chance.
Sample-to-Sample Variability: Natural variability occurring by chance.
Ethics and Biases in Data Analysis
Ethical Considerations
Ethics play a crucial role in statistics, especially with the rise of big data and automated decision-making.
Data Privacy: Protecting personal information collected in studies.
Data Security: Ensuring sensitive data is encrypted and inaccessible to unauthorized parties.
Decision Making: Algorithms trained on large databases can make important decisions, but may carry biases or use inaccurate data.
