 Back
BackSummarising Data: Numerical Methods in Statistics
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Measures of Variability
Interquartile Range (IQR)
The interquartile range (IQR) is a measure of variability that focuses on the middle 50% of the data, reducing the influence of extreme values. It is calculated as the difference between the third quartile (Q3) and the first quartile (Q1):
Formula:
Advantages: Easy to interpret, not influenced by extreme values.
Disadvantage: Only considers the middle 50% of the data.
Example: For starting salaries of 12 graduates, if and , then .
Variance
Variance measures the average squared deviation from the mean, utilizing all data points. It can be defined for both populations and samples:
Population variance:
Sample variance:
Interpretation: Variance is expressed in squared units of the variable.
Standard Deviation
The standard deviation is the positive square root of the variance, representing the average deviation of observations from their mean. It is expressed in the same units as the data.
Population standard deviation:
Sample standard deviation:
Example: For class sizes [46, 54, 42, 46, 32] with , .
Coefficient of Variation (CV)
The coefficient of variation is a relative measure of variability, expressing the standard deviation as a percentage of the mean:
Formula:
Interpretation: Useful for comparing variability between datasets with different units or means.
Example: If and , .
Measures of Distribution Shape, Relative Location, and Detecting Outliers
Distribution Shapes
Understanding the shape of a distribution is essential for data analysis. Common shapes include:
Skewed to the left (Negative skew): The left tail is longer; more outliers on the left.
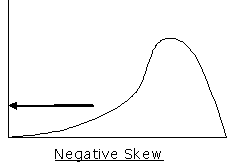
Skewed to the right (Positive skew): The right tail is longer; more outliers on the right.
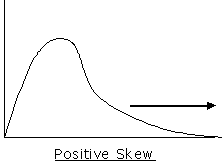
Symmetric: Both tails are of equal length; the normal distribution is a key example.
Z-scores
Z-scores measure the relative location of a value within a dataset, indicating how many standard deviations an observation is from the mean:
Formula:
Interpretation: Negative z-scores are below the mean; positive are above.
Example: For , , , (1.25 standard deviations above the mean).
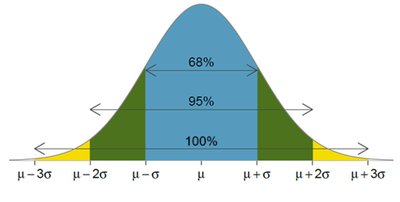
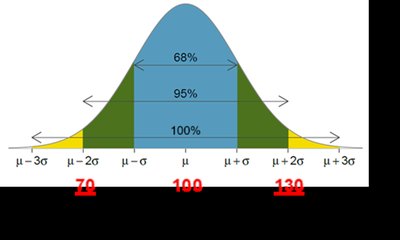
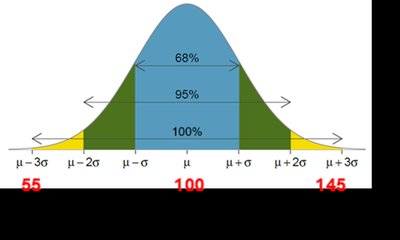
The Empirical Rule
The empirical rule applies to bell-shaped (normal) distributions, describing the percentage of data within certain standard deviations from the mean:
Approximately 68% within 1 standard deviation
Approximately 95% within 2 standard deviations
Approximately 100% within 3 standard deviations
Examples Using the Empirical Rule
IQ scores between 85 and 115 (mean 100, SD 15): 68% of people
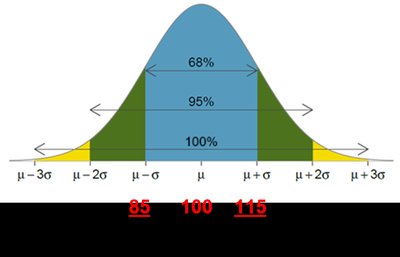
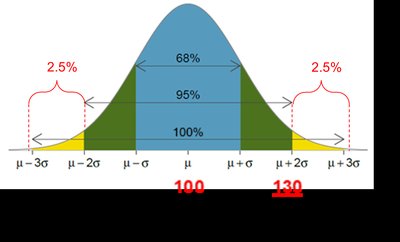
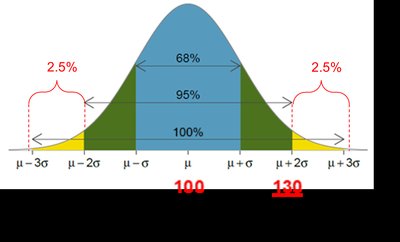
IQ scores between 70 and 130: 95% of people
IQ scores above 130: 2.5% of people
16th percentile (P16): IQ = 85
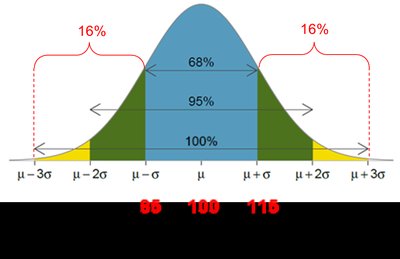
84th percentile (P84): IQ = 115
Outlier detection: IQ = 160 is an outlier (z = 4, more than 3 SDs from mean)
Detecting Outliers
Outliers are extreme values that may affect statistical analysis. Two main methods for detecting outliers:
For bell-shaped distributions: Any value with or is considered an outlier.
For non-bell-shaped distributions: Calculate lower and upper limits:
Lower limit:
Upper limit:
Values outside these limits are outliers.
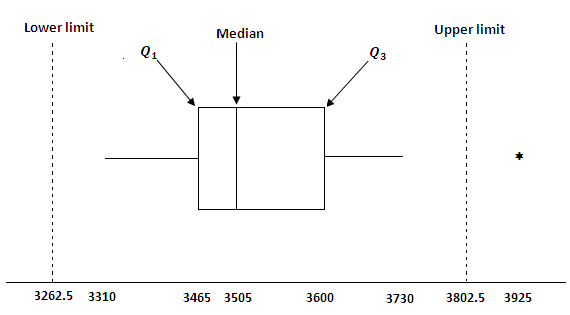
Five-Number Summaries and Boxplots
Five-Number Summary
The five-number summary consists of:
Minimum
First quartile (Q1)
Median (Q2)
Third quartile (Q3)
Maximum
Box Plot
A box plot is a graphical summary based on the five-number summary, useful for visualizing the spread and detecting outliers:
The box spans Q1 to Q3 (middle 50% of data).
A line marks the median; an X may indicate the mean.
Whiskers extend to the smallest/largest values within 1.5(IQR) of Q1/Q3.
Outliers are plotted as individual points.
Box plots can indicate skewness by the position of the median and the length of whiskers.
Measures of Association Between Two Variables
Covariance
Covariance measures the direction of the linear relationship between two variables X and Y:
Formula:
Interpretation:
: Positive linear relationship
: Negative linear relationship
: No linear relationship
Limitation: Covariance does not indicate the strength of the relationship due to dependence on units.
Correlation Coefficient
The correlation coefficient (r) measures the strength and direction of the linear relationship between two variables, standardized to be unitless:
Formula:
Range:
Interpretation:
: Perfect positive linear relationship
: Perfect negative linear relationship
: No linear relationship

The Weighted Mean and Grouped Data
Weighted Mean
When observations have different levels of importance, the weighted mean is used:
Formula:
Example: Calculating the mean cost per pound for purchases with different quantities.
Grouped Data
For data presented in frequency distributions, the mean and variance can be estimated using group midpoints:
Sample mean:
Sample variance:
Where: is the midpoint of the ith group, is the frequency, and is the total number of observations.
Summary Table: Key Measures and Their Formulas
Measure | Formula | Interpretation |
|---|---|---|
Interquartile Range (IQR) | Middle 50% spread | |
Variance (Sample) | Average squared deviation | |
Standard Deviation (Sample) | Average deviation from mean | |
Coefficient of Variation | Relative variability (%) | |
Z-score | Relative position in SD units | |
Covariance | Direction of linear relationship | |
Correlation Coefficient | Strength and direction of linear relationship | |
Weighted Mean | Mean with weights | |
Grouped Data Mean | Mean for grouped data |
