 Back
BackUnit 1: Foundations of Elementary Statistics – Data, Sampling, and Descriptive Measures
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Statistics Basics
Descriptive vs. Inferential Statistics
Statistics is the science of collecting, organizing, analyzing, and interpreting data. It is divided into two main branches: descriptive statistics and inferential statistics.
Descriptive Statistics: Methods for organizing and summarizing information. Examples include calculating the average salary for a career, the number of home runs in a season, or the frequency of grades in a class. These statistics describe data from a full population or dataset without making predictions.
Inferential Statistics: Methods for drawing and measuring the reliability of conclusions about a population based on information obtained from a sample. For example, testing whether the thickness of baseball laces affects home run rates by sampling games and comparing outcomes.
Population: The entire collection of individuals or items under consideration. Sample: A subset of the population from which data is actually collected.
Variables: Characteristics that vary from one individual or item to another. Variables can be:
Qualitative (Categorical): Non-numeric, sorts into categories (e.g., hair color, model of car).
Quantitative: Numeric, can be further classified as:
Discrete: Countable values (e.g., number of pets, shoe size).
Continuous: Any value within an interval (e.g., foot length, time for commute).
Example: The number of home runs in a season is a discrete quantitative variable, while the thickness of laces is a continuous quantitative variable.
Organizing Data
Frequency and Relative Frequency
To summarize data, we use frequency (the number of times a value occurs) and relative frequency (the proportion of times a value occurs relative to the total number of observations). Relative frequency can be expressed as a fraction, decimal, or percentage.
Grade | Frequency | Relative Frequency |
|---|---|---|
A | 4 | 0.16 |
B | 11 | 0.44 |
C | 7 | 0.28 |
F | 3 | 0.12 |
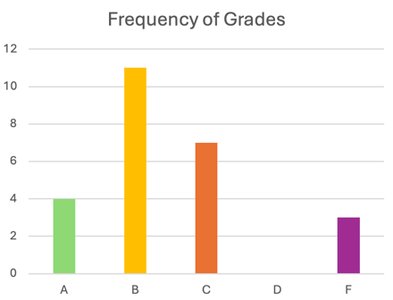
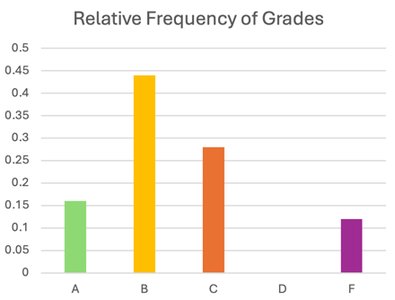
Bar charts and pie charts are common for qualitative data. Bar charts display frequencies or relative frequencies for categories, while pie charts show proportions as slices of a circle.
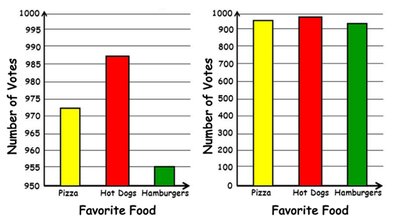
Misleading Graphs
Graphs can be misleading if they use truncated axes or improper scaling. Always check that the y-axis starts at zero and that the scale is consistent.

Organizing Quantitative Data
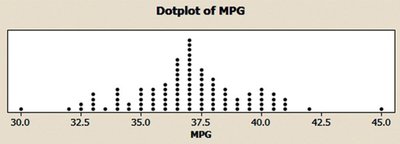
Stem-and-Leaf Diagrams and Dot Plots
Stem-and-leaf diagrams organize data to show its shape and distribution, preserving the original data values. Dot plots display each data point as a dot above a number line, useful for small to moderate-sized data sets.

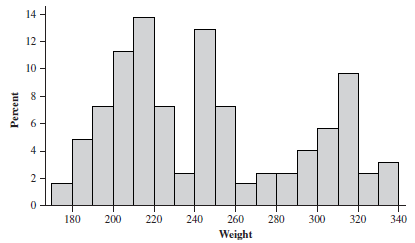
Histograms
Histograms are used for quantitative data, grouping values into intervals (bins or classes). The number of classes should be sufficient to show the data's characteristics but not so many as to obscure patterns. Each observation must belong to one and only one class, and class widths should be equal when possible.
Distribution Shapes
Uniform: All values have approximately the same frequency.
Symmetric: Left and right sides are mirror images.
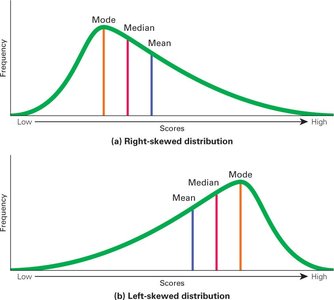
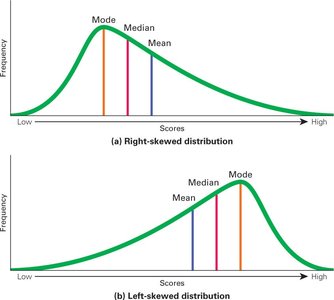
Positively Skewed (Right): Long tail to the right; mean is to the right of the median.
Negatively Skewed (Left): Long tail to the left; mean is to the left of the median.
Unimodal, Bimodal, Multimodal: One, two, or more peaks in the distribution.
Sampling Methods
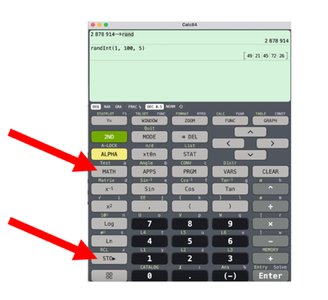
Simple Random Sampling
In simple random sampling, every possible sample of a given size has an equal chance of being selected. Random number generators or tables can be used to select samples.

Other Sampling Designs
Stratified Sampling: Divide the population into groups (strata) and randomly sample from each group.
Cluster Sampling: Divide the population into clusters, randomly select clusters, and sample all or some items within selected clusters.
Systematic Sampling: Select every kth item from a list after a random start.
Convenience Sampling: Select items that are easiest to obtain (often biased).
Descriptive Measures
Measures of Central Tendency
Sample Mean (\( \bar{x} \)): The average of sample data values. $\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i$
Population Mean (\( \mu \)): The average of all population values. $\mu = \frac{1}{N} \sum_{i=1}^{N} x_i$
Median: The middle value when data are ordered.
Mode: The value that occurs most frequently.
Measures of Variation (Spread)
Range: Difference between the maximum and minimum values.
Interquartile Range (IQR): Difference between the third and first quartiles (middle 50% of data).
Variance: Average squared deviation from the mean. Population variance: $\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2$ Sample variance: $s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2$
Standard Deviation: Square root of the variance. Population: $\sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2}$ Sample: $s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2}$
Empirical Rule (for Normal Distributions)
For bell-shaped (normal) distributions:
About 68% of data falls within 1 standard deviation of the mean.
About 95% within 2 standard deviations.
About 99.7% within 3 standard deviations.
Five-Number Summary and Box Plots
Five-Number Summary
The five-number summary consists of the minimum, first quartile (Q1), median (Q2), third quartile (Q3), and maximum. Box plots (box-and-whisker plots) visually display this summary and help identify outliers.
Outliers
Potential outliers are values more than 1.5 × IQR from the quartiles. Extreme outliers are more than 3 × IQR from the quartiles. Outliers should be examined for possible data entry errors or special causes.
Trimmed Mean
A trimmed mean is calculated by removing a specified percentage of the smallest and largest values before computing the mean. This reduces the effect of outliers.
Summary Table: Types of Data and Graphs
Data Type | Graphical Display |
|---|---|
Qualitative (Categorical) | Bar Chart, Pie Chart |
Quantitative (Discrete/Continuous) | Histogram, Stem-and-Leaf, Dot Plot, Box Plot |
Example: For the variable "current year in school" (first year, sophomore, junior, senior), a bar chart or pie chart is appropriate. For "time to drive home," a histogram or box plot is suitable.
Additional info: These foundational concepts are essential for understanding later topics such as probability, sampling distributions, confidence intervals, and hypothesis testing.
