 Back
BackChapter 12: The Genetic Code and Prokaryotic Transcription – Study Notes
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Genetic Code
Introduction to the Genetic Code
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins by living cells. It is fundamental to understanding how genes direct the synthesis of proteins, which are essential for cellular function.
Key Point 1: The genetic code is composed of nucleotide triplets called codons, each of which specifies a particular amino acid.
Key Point 2: There are 20 standard amino acids, and the code must accommodate all of them.
Example: The codon AUG codes for the amino acid methionine and also serves as the start signal for translation.

Evolution of the Genetic Code
The discovery and understanding of the genetic code involved contributions from many scientists. Early work identified essential amino acids and their dietary importance, while later experiments established the triplet nature of the code.
Key Point 1: William Rose identified essential amino acids in the human diet.
Key Point 2: The code evolved from single-base, double-base, to triplet-base hypotheses, with the triplet code providing enough combinations (64) to encode all amino acids.
Example: With four bases (A, T/U, G, C), a triplet code yields possible codons.
Triplet Nature of the Genetic Code
The genetic code is read in sets of three nucleotides, known as codons. Each codon corresponds to a specific amino acid or a stop signal during translation.
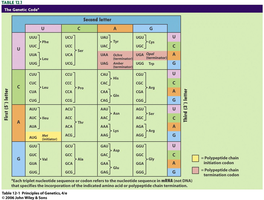
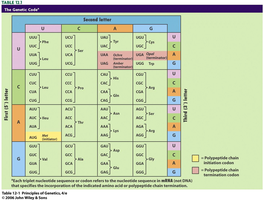
Key Point 1: The triplet code allows for 64 possible codons, more than enough for the 20 amino acids.
Key Point 2: Some amino acids are specified by more than one codon, making the code degenerate.
Example: The codons UUU and UUC both code for phenylalanine.
Properties of the Genetic Code
The genetic code possesses several important properties that ensure accurate translation of genetic information.
Key Point 1: Degeneracy: Multiple codons can code for the same amino acid.
Key Point 2: Non-overlapping: Codons are read one after another, without overlap.
Key Point 3: Universal: The code is nearly universal across all organisms.
Key Point 4: Start and Stop Codons: AUG is the start codon; UAA, UAG, and UGA are stop codons.

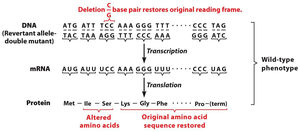
Reading Frame and Mutations
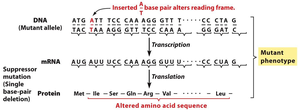
The reading frame is critical for correct translation. Mutations such as insertions or deletions can shift the reading frame, leading to altered protein products.
Key Point 1: Frameshift mutations occur when nucleotides are inserted or deleted, changing the reading frame.
Key Point 2: Suppressor mutations can restore the original reading frame by compensating for the initial mutation.
Example: Insertion of a single base pair alters the reading frame, but a subsequent deletion can restore it.
Beadle and Tatum’s Experiment
Beadle and Tatum’s experiment with Neurospora led to the one gene-one enzyme hypothesis, establishing the direct relationship between genes and metabolic pathways.
Key Point 1: Mutations in genes can lead to loss of enzyme function.
Key Point 2: Each gene encodes a specific enzyme, supporting the concept of gene-protein correspondence.
Example: Mutant strains of Neurospora could not grow on minimal medium unless supplemented with the missing nutrient.

Prokaryotic Transcription
Overview of Transcription in Prokaryotes
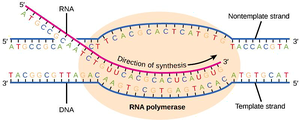
Transcription is the process by which genetic information from DNA is copied into RNA. In prokaryotes, this process is carried out by RNA polymerase and involves several distinct stages.
Key Point 1: Transcription does not require a primer or helicase.
Key Point 2: RNA is synthesized in the 5’ to 3’ direction.
Key Point 3: Bacterial mRNA can be polycistronic, encoding multiple polypeptides.
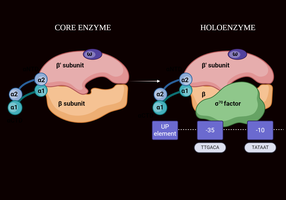
RNA Polymerase: Core vs. Holoenzyme
RNA polymerase exists in two forms: the core enzyme and the holoenzyme. The holoenzyme includes the sigma factor, which is essential for promoter recognition.
Key Point 1: The core enzyme is responsible for RNA synthesis but cannot initiate transcription alone.
Key Point 2: The holoenzyme includes the sigma factor, which enables the enzyme to bind to specific promoter sequences.
Example: The sigma factor dissociates after initiation, leaving the core enzyme to continue elongation.
Promoter Structure and Function
Promoters are DNA sequences that define where transcription begins. In prokaryotes, promoters contain conserved regions such as the -35 and -10 sequences (Pribnow box).
Key Point 1: The -35 and -10 regions are recognized by the sigma factor.
Key Point 2: The transcriptional start site is designated as +1.
Example: The Pribnow box (TATAAT) is located at the -10 position.
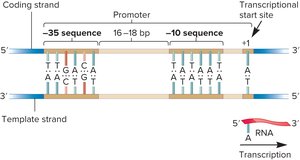
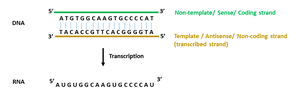
Coding vs. Template Strand
During transcription, only one strand of DNA serves as the template. The coding strand has the same sequence as the RNA (except for T/U), while the template strand is used for RNA synthesis.
Key Point 1: The template strand is read by RNA polymerase to synthesize RNA.
Key Point 2: The coding strand is not transcribed but matches the RNA sequence.
Example: The direction of transcription is determined by the promoter.
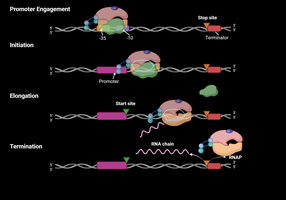
Stages of Transcription: Initiation, Elongation, Termination
Transcription proceeds through three main stages: initiation, elongation, and termination. Each stage involves specific molecular events and factors.
Key Point 1: Initiation: RNA polymerase binds to the promoter and begins RNA synthesis.
Key Point 2: Elongation: RNA polymerase moves along the DNA, synthesizing RNA.
Key Point 3: Termination: Transcription ends when RNA polymerase encounters a terminator sequence.
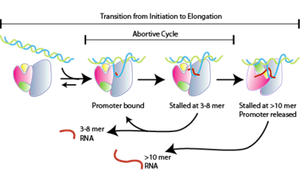
Transcription Termination: Rho-dependent and Rho-independent
Termination of transcription in prokaryotes can occur via two mechanisms: rho-dependent and rho-independent.
Key Point 1: Rho-dependent termination requires the rho protein, a helicase that uses ATP to release the RNA transcript.
Key Point 2: Rho-independent termination relies on a GC-rich stem-loop structure followed by a uracil-rich sequence, causing RNA polymerase to dissociate.
Example: The stem-loop structure destabilizes the RNA-DNA hybrid, facilitating transcript release.
Directionality and Promoter Specificity
Each gene uses one DNA strand as a template, but the template strand can vary between genes. Promoters specify the direction of transcription, which can differ for adjacent genes.
Key Point 1: Promoters determine which strand is used as the template.
Key Point 2: Adjacent genes may be transcribed in opposite directions.
Example: The orientation of the promoter dictates the direction of RNA synthesis.
