 Back
BackGenetic Variant Nomenclature and Interpretation: Study Notes for Genetics Students
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Genetic Variant Nomenclature
Introduction to Variant Nomenclature
Accurate and standardized nomenclature is essential in genetics for describing sequence variants at the DNA, RNA, and protein levels. This ensures clear communication in clinical diagnostics, research, and literature, especially since a single gene may have multiple names or transcripts, and variants can be described differently across sources.
HGVS Nomenclature: The Human Genome Variation Society (HGVS) provides internationally accepted guidelines for naming genetic variants.
Reference Sequences: Variants are described relative to a reference sequence, which may differ between transcripts or genome builds.
Importance: Consistent nomenclature prevents misinterpretation and ensures that clinical decisions are based on precise variant identification.

Reference Sequence Types and Notation
Different reference sequences are used depending on the context:
c. – Coding DNA sequence
g. – Genomic DNA sequence
m. – Mitochondrial DNA sequence
r. – RNA sequence
p. – Protein sequence
Each reference sequence may have a unique accession number and version, which is critical for reproducibility and clarity.

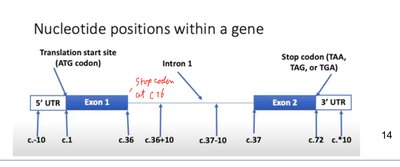
Nucleotide Numbering and Variant Description
Nucleotide positions are numbered starting from the A of the ATG translation start codon as +1. Positions upstream (5') are negative, and positions downstream (3') of the stop codon are positive. Intronic positions are described relative to the nearest exon boundary.
Example: c.77+1G refers to the first nucleotide in the intron after coding base 77.
Insertions: "ins" after the flanking nucleotides, e.g., c.76_77insT.
Deletions: "del" after the first and last nucleotide deleted, e.g., c.76_78del.
Duplications: "dup" after the duplicated nucleotide, e.g., c.76dupT.

Protein-Level Variant Notation
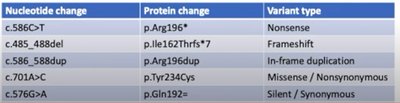
Protein changes are described using the three-letter amino acid code, with the position and the new amino acid. For example, p.Gly144Val indicates a glycine to valine substitution at position 144. Silent changes (no amino acid change) must also be described at the DNA level due to possible effects on splicing.
Frameshift: Indicated by "fs" and the new stop codon position, e.g., p.Arg97Hisfs*5.
Stop Codons: Denoted as "*", "Ter", or "X" (old literature).


Types of Sequence Variants
Variants can be classified by their effect on the protein:
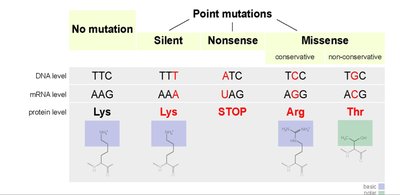
Missense: Amino acid change (e.g., p.Gly144Val).
Nonsense: Introduction of a premature stop codon (e.g., p.Arg196*).
Silent: No change in amino acid (e.g., p.Gln192=).
Frameshift: Insertion or deletion not divisible by three, altering the reading frame.
In-frame: Insertions or deletions divisible by three, not altering the reading frame.

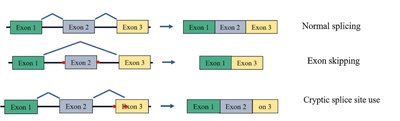
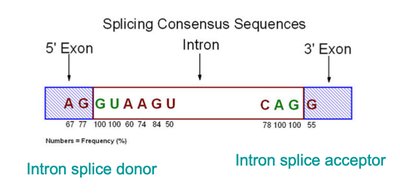
Splicing Variants
Variants affecting splicing can lead to exon skipping, activation of cryptic splice sites, or intron retention, often resulting in abnormal or truncated proteins.
Consensus Sequences: Splice donor (5' GU) and acceptor (3' AG) sites are critical for correct splicing.
Consequences: Aberrant splicing can cause loss of function or disease phenotypes.
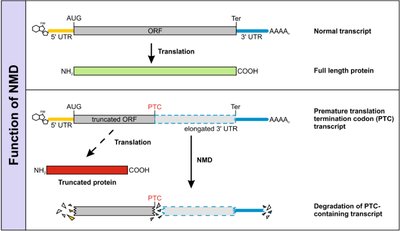
Nonsense-Mediated Decay (NMD)
NMD is a cellular mechanism that degrades mRNA transcripts containing premature termination codons (PTCs), preventing the production of truncated, potentially harmful proteins.
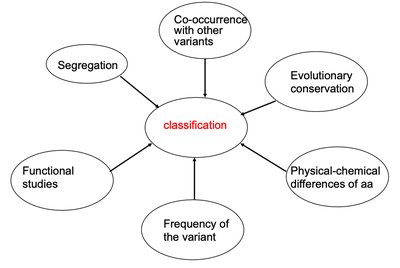
Classification of Variants
Variants are classified based on their predicted effect on protein function, frequency in the population, segregation with disease, evolutionary conservation, and results from functional studies.
Pathogenicity Classes: Benign, likely benign, uncertain significance (VUS), likely pathogenic, pathogenic.
Examples and Applications
Gene and Variant Examples
CFTR: The gene responsible for cystic fibrosis, with variants described using standardized nomenclature.
FH: Example of variant notation: NM_000143.3:c.431G>T p.(Gly144Val), where the reference sequence version is critical for correct interpretation.
Summary Table: Variant Types and Effects
Variant Type | Notation Example | Effect |
|---|---|---|
Substitution | c.76A>C | Missense, nonsense, or silent |
Deletion | c.76_78del | Frameshift or in-frame deletion |
Insertion | c.76_77insT | Frameshift or in-frame insertion |
Duplication | c.76dupT | Frameshift or in-frame duplication |
Key Equations
Hardy-Weinberg Principle: For two alleles,
Additional info:
Understanding variant nomenclature is foundational for interpreting genetic test results, conducting research, and communicating findings in medical genetics. Mastery of these conventions is essential for all genetics professionals.
