 Back
BackCh 18 Genomics, Bioinformatics, and Proteomics: Foundations and Applications
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Genomics, Bioinformatics, and Proteomics
Introduction to Genomics and Bioinformatics
Genomics is the comprehensive study of genomes, encompassing the structure, function, evolution, and mapping of genetic material in organisms. Bioinformatics applies mathematical and computational tools to organize, analyze, and interpret vast amounts of genetic data, including gene structure, sequence, expression, and protein function.
Genomics provides insights into the complete DNA content of organisms, enabling comparative and functional studies.
Bioinformatics supports the management and analysis of genetic and protein data, facilitating discoveries in gene function and regulation.
Whole-Genome Sequencing (WGS)
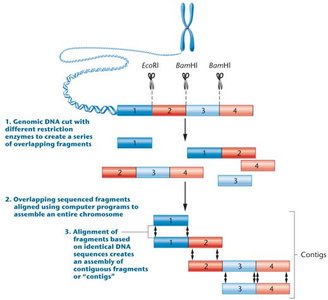
Whole-genome sequencing (WGS), also known as shotgun sequencing, is the primary method for determining the complete DNA sequence of an organism's genome. The process involves fragmenting DNA, sequencing the fragments, and assembling them into a continuous sequence using computational tools.
Steps in WGS:
Shearing or digestion of genomic DNA with restriction enzymes to create overlapping fragments.
Sequencing of these fragments.
Alignment of sequenced fragments using computer programs.
Contig overlap—identifying overlapping sequences to assemble the genome.
Gene identification by bioinformatics analysis.
Contigs: Overlapping DNA fragments that are assembled into continuous sequences.
Bioinformatics Applications
Bioinformatics utilizes algorithm-based software to align DNA sequences, identify genes, and predict gene function. Sequence alignment is crucial for reconstructing chromosomes and comparing genetic material across species.
DNA Sequence Alignment: Aligns similar sequences for comparison and assembly.
Applications:
Comparing DNA sequences
Gene identification
Finding regulatory regions (promoters, enhancers)
Predicting amino acid sequences
Deducing evolutionary relationships
GenBank and BLAST
GenBank, maintained by the National Center for Biotechnology Information (NCBI), is the largest public DNA sequence database. The Basic Local Alignment Search Tool (BLAST) is a software application for comparing new sequences to known sequences in databases, calculating identity values and E-values to assess similarity.
GenBank: Assigns accession numbers to sequences for retrieval and analysis.
BLAST: Identifies sequence similarity and evolutionary relationships.

Gene Annotation and Hallmark Features
Gene annotation involves identifying the structural and functional elements of genes within a DNA sequence. Hallmark features include exons, introns, regulatory sequences (promoters, enhancers, silencers), untranslated regions (UTRs), and termination sites.
Open Reading Frames (ORFs): Sequences that can be translated into proteins, typically starting with ATG and ending with TAA, TAG, or TGA (stop codons).
Gene-regulatory sequences: Located upstream of coding regions, essential for gene expression control.

Predicting Gene and Protein Functions
Functional genomics interprets DNA sequences to establish gene functions, often using experimental validation. Sequence similarity searches (e.g., BLAST) can infer gene function based on homology to known genes.
Homologous Genes: Genes related by descent from a common ancestor. Orthologs are homologous genes in different species.
Protein Domains and Motifs
Gene sequences can predict polypeptide sequences, which are analyzed for specific protein domains and motifs. These structural features help predict protein function and evolutionary relationships.
Protein Domains: Functional regions such as ion channels or membrane-spanning regions.
Motifs: Structural patterns like helix-turn-helix, leucine zipper, or zinc-finger motifs.
Major Features of the Human Genome
The human genome contains approximately 3.1 billion nucleotides, with protein-coding sequences comprising only about 2%. The genome is highly dynamic, with significant portions derived from transposable elements and repetitive DNA. Alternative splicing allows a relatively small number of genes (~20,000) to produce a much larger diversity of proteins.
Feature | Description |
|---|---|
Genome Size | ~3.1 billion base pairs |
Protein-coding Genes | ~20,000 |
Protein-coding DNA | <2% of genome |
Alternative Splicing | >50% of genes produce multiple proteins |
Gene Distribution | Non-uniform; gene-rich and gene-poor regions |
Introns | Human genes have more and larger introns than invertebrates |
Human Genome Project (HGP) and Its Impact
The Human Genome Project (HGP) revealed that less than 2% of the genome codes for proteins and identified about 20,000 protein-coding genes. Alternative splicing explains the discrepancy between gene number and protein diversity. The HGP has enabled the identification of disease genes and the development of new treatment strategies.

Individual Variations in the Human Genome
Human genomes are 99.9% identical, with most variation arising from single-nucleotide polymorphisms (SNPs) and copy number variations (CNVs). These variations can influence disease susceptibility and other traits.
Omics Disciplines
"Omics" refers to comprehensive fields of study in biology, including:
Proteomics (proteins)
Metabolomics (metabolites)
Glycomics (carbohydrates)
Toxicogenomics (toxic responses)
Metagenomics (microbial communities)
Pharmacogenomics (drug responses)
Transcriptomics (RNA transcripts)
Whole-Exome Sequencing (WES)
Whole-exome sequencing targets only the exons (protein-coding regions) of the genome, enabling efficient identification of mutations related to disease. However, it does not capture regulatory regions that influence gene expression.
ENCODE Project
The Encyclopedia of DNA Elements (ENCODE) project uses experimental and computational approaches to identify functional elements in the genome, such as transcription start sites, promoters, and enhancers.
Nutrigenomics
Nutrigenomics studies the interaction between nutrition and genes, aiming to provide personalized dietary recommendations based on genetic makeup.
Stone-Age Genomics
Stone-age genomics analyzes ancient DNA from fossils and preserved tissues to study evolutionary relationships among extinct and extant species.
Comparative Genomics
Comparative genomics compares the genomes of different organisms to understand gene function, evolution, and the relationship between organisms and their environments. It is essential for gene discovery and the development of model organisms for human disease research.
Organism | Genome Size | Chromosome Number | Gene Number | % Genes Shared with Humans |
|---|---|---|---|---|
Human | 3.1 Gb | 46 | ~20,000 | 100 |
Chimpanzee | 3 Gb | 48 | ~20,000-24,000 | 98 |
Mouse | ~2.5 Gb | 40 | ~30,000 | 80 |
Yeast | 12 Mb | 32 | ~5,700 | 30 |
Fruit fly | 165 Mb | 8 | ~13,600 | 50 |
Rice | 389 Mb | 24 | ~41,000 | Not determined |
The Neanderthal Genome and Modern Humans
Sequencing of Neanderthal DNA has revealed that modern non-African humans possess 1–4% Neanderthal-derived sequences, indicating interbreeding between the two species. Comparative genomics has identified regions of rapid human evolution since divergence from Neanderthals.
Metagenomics and the Human Microbiome Project
Metagenomics uses WGS to analyze genomes from environmental samples, revealing the diversity of microbial communities. The Human Microbiome Project (HMP) aims to sequence the genomes of microorganisms living in and on humans, providing insights into health and disease.
Proteomics: Identification and Analysis of Proteins
Proteomics is the large-scale study of proteins, including their identification, characterization, and quantification. It provides information on protein structure, function, interactions, and modifications, and is crucial for understanding cellular processes and disease mechanisms.
Proteomes: The complete set of proteins encoded by a genome.
Applications: Comparing protein expression in normal and diseased tissues, identifying biomarkers.
Proteomics Technologies
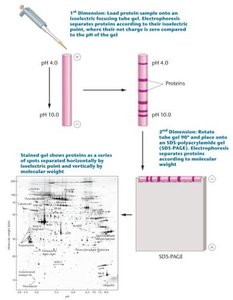
Two-Dimensional Gel Electrophoresis (2DGE)
2DGE separates proteins based on isoelectric point (pH) and molecular weight, allowing high-resolution analysis of complex protein mixtures.
Mass Spectrometry (MS)
Mass spectrometry analyzes ionized protein fragments to determine their mass-to-charge ratio, enabling identification of unknown proteins and analysis of post-translational modifications.

Additional info: The integration of genomics, bioinformatics, and proteomics is transforming our understanding of biology, disease, and evolution, providing powerful tools for research and medicine.
