 Back
BackThe Genetic Code and Prokaryotic Transcription: Study Notes
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Chapter 12: The Genetic Code and Prokaryotic Transcription
Introduction
This chapter explores the molecular basis of genetic information flow from DNA to protein, focusing on the genetic code and the mechanisms of transcription in prokaryotes. Understanding these processes is fundamental to genetics, as they explain how genetic information is expressed and regulated in living organisms.
The Genetic Code
Definition and Historical Context
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins by living cells. Each group of three nucleotides (codon) in mRNA specifies a particular amino acid.
20 amino acids are used to build proteins in all living organisms.
The code is nearly universal among all organisms.
Early experiments by scientists such as Beadle and Tatum established the connection between genes and enzymes, leading to the "one gene-one enzyme" hypothesis.

Properties of the Genetic Code
Triplet Code: Each amino acid is encoded by a sequence of three nucleotides (codon).
Degeneracy: Most amino acids are specified by more than one codon.
Non-overlapping: Codons are read one after another without overlapping.
Comma-less: There are no gaps or punctuation between codons.
Universal: With few exceptions, the genetic code is the same in all organisms.
Start and Stop Codons: AUG is the start codon (methionine); UAA, UAG, and UGA are stop codons.
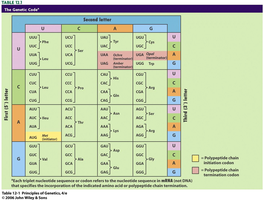
Reading the Genetic Code
The genetic code is read in sets of three nucleotides (codons) from a fixed starting point. The reading frame is critical; shifting the frame alters the resulting protein sequence.
Single base code: 4 possible codes (insufficient for 20 amino acids).
Double base code: 16 possible codes (still insufficient).
Triplet base code: 64 possible codes (sufficient for all amino acids and stop signals).
Mutations and the Genetic Code
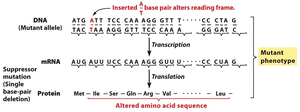
Mutations can alter the reading frame or the codons, leading to changes in the protein product.
Frameshift mutations: Insertions or deletions of nucleotides that are not multiples of three shift the reading frame, often resulting in nonfunctional proteins.
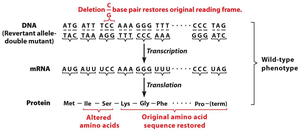
Suppressor mutations: A second mutation can restore the original reading frame, partially or fully rescuing protein function.
Insertion of three base pairs: Does not change the reading frame but adds an extra amino acid.
Beadle and Tatum’s Experiment
Beadle and Tatum used the bread mold Neurospora crassa to demonstrate that genes encode enzymes. By inducing mutations and analyzing nutritional requirements, they formulated the "one gene-one enzyme" hypothesis, which was foundational for molecular genetics.

Prokaryotic Transcription
Overview of Transcription
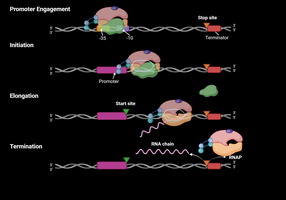
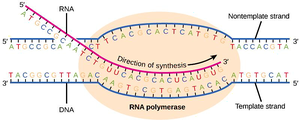
Transcription is the process by which RNA is synthesized from a DNA template. In prokaryotes, this process is carried out by RNA polymerase and involves three main stages: initiation, elongation, and termination.
No helicase or primer required: RNA polymerase unwinds DNA and initiates RNA synthesis de novo.
Direction: RNA is synthesized in the 5’ to 3’ direction.
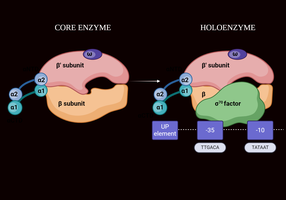
RNA Polymerase: Core Enzyme vs. Holoenzyme
Core enzyme: Composed of multiple subunits (α2ββ’ω), responsible for RNA synthesis.
Holoenzyme: Core enzyme plus the sigma (σ) factor, which is required for promoter recognition and initiation of transcription.
Sigma factor: Directs RNA polymerase to specific promoter sequences.
Promoters and the Pribnow Box
Promoters are DNA sequences that define where transcription of a gene by RNA polymerase begins. In prokaryotes, two key regions are the -35 and -10 sequences (the latter is also called the Pribnow box).
-35 sequence: TTGACA (consensus sequence)
-10 sequence (Pribnow box): TATAAT (consensus sequence)
These sequences are recognized by the sigma factor of RNA polymerase.

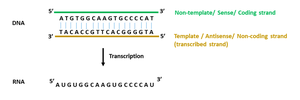
Coding vs. Template Strand
During transcription, only one strand of DNA serves as the template for RNA synthesis. The coding (sense) strand has the same sequence as the RNA (except T is replaced by U), while the template (antisense) strand is used for base pairing.
Stages of Transcription
Initiation: RNA polymerase holoenzyme binds to the promoter, DNA unwinds, and RNA synthesis begins at the +1 site.
Elongation: RNA polymerase moves along the DNA, synthesizing RNA in the 5’ to 3’ direction.
Termination: RNA synthesis ends, and the RNA transcript is released.
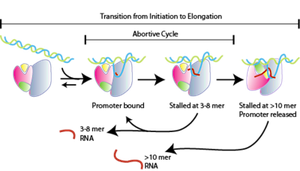
Types of Transcription Termination
Rho-dependent termination: Requires the rho (ρ) protein, a helicase that binds to the RNA and moves toward the RNA polymerase, causing dissociation at a specific site.
Rho-independent termination: Relies on the formation of a GC-rich stem-loop structure in the RNA, followed by a uracil-rich sequence, causing the RNA polymerase to pause and dissociate.
Key features of rho-independent termination:
Stem-loop structure upstream of a uracil-rich sequence
Weak A-U base pairing facilitates transcript release
Directionality of Transcription
Each gene uses one DNA strand as a template, but the template strand can differ between adjacent genes. The promoter determines the direction of transcription for each gene.
Summary Table: Properties of the Genetic Code
Property | Description |
|---|---|
Triplet | Three nucleotides (codon) specify one amino acid |
Degenerate | More than one codon can specify the same amino acid |
Non-overlapping | Codons are read sequentially, without overlap |
Comma-less | No punctuation between codons |
Universal | Same code used by almost all organisms |
Start/Stop Codons | AUG (start); UAA, UAG, UGA (stop) |
Key Equations
Number of possible codons (triplet code):
Conclusion
The genetic code and the process of transcription are central to the flow of genetic information in cells. Understanding these mechanisms provides the foundation for advanced topics in genetics, including gene regulation, mutation, and biotechnology.
