 Back
BackThe Genetic Code and Translation: Structure, Function, and Mechanisms
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Chapter 13: The Genetic Code and Transcription
Introduction to the Genetic Code
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins by living cells. This code is fundamental to the process of gene expression, which involves the transcription of DNA into RNA and the translation of RNA into protein.
Features of the Genetic Code
Triplet Code: The genetic code is read in groups of three ribonucleotide bases, called codons, on the mRNA.
Unambiguous: Each codon specifies only one amino acid.
Degenerate: Most amino acids are encoded by more than one codon.
Start and Stop Signals: Specific codons signal the initiation (AUG) and termination (UAA, UAG, UGA) of translation.
Commaless and Nonoverlapping: Codons are read sequentially without gaps or overlap.
Colinear: The sequence of codons in a gene corresponds directly to the sequence of amino acids in the protein.
Nearly Universal: The genetic code is conserved across most organisms, with only minor exceptions.
Deciphering the Genetic Code
Early experiments, such as the triplet binding assay by Nirenberg and Leder, established the operational patterns of the code. By mixing ribosomes, synthetic mRNA triplets, and charged tRNAs, researchers identified which codons corresponded to which amino acids.
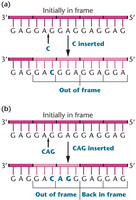
Reading Frame and Frameshift Mutations
The reading frame is the way nucleotides in mRNA are grouped into codons. Insertions or deletions can shift the reading frame, causing frameshift mutations that alter downstream amino acid sequences.
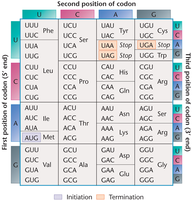
The Coding Dictionary and Codon Table
The genetic code consists of 64 codons that specify 20 amino acids and three stop signals. Only methionine (AUG) and tryptophan (UGG) are encoded by a single codon; all others are degenerate.
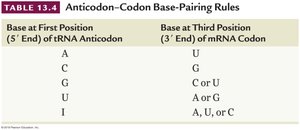
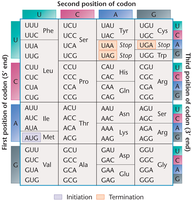
The Wobble Hypothesis
The wobble hypothesis explains that the third base of a codon is often less critical for specifying an amino acid, allowing some tRNAs to pair with more than one codon. This flexibility contributes to the degeneracy of the code.
Base at First Position (5' End) of tRNA Anticodon | Base at Third Position (3' End) of mRNA Codon |
|---|---|
A | U |
C | G |
G | C or U |
U | A or G |
I | A, U, or C |
Initiation and Termination Codons
Initiator Codon: AUG (methionine) signals the start of translation.
Termination Codons: UAA, UAG, and UGA signal the end of translation and are not recognized by tRNAs.
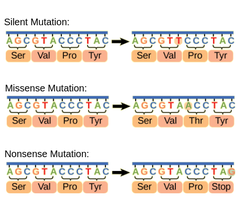
Types of Point Mutations
Silent Mutation: Alters a nucleotide but does not change the amino acid.
Missense Mutation: Changes a nucleotide and results in a different amino acid.
Nonsense Mutation: Changes a nucleotide and creates a stop codon, truncating the protein.
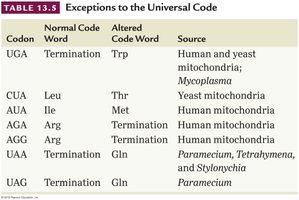
Exceptions to the Universal Code
While the genetic code is nearly universal, some exceptions exist, particularly in mitochondrial DNA and certain unicellular organisms. For example, UGA codes for tryptophan in human mitochondria instead of serving as a stop codon.
Codon | Normal Code Word | Altered Code Word | Source |
|---|---|---|---|
UGA | Termination | Trp | Human and yeast mitochondria; Mycoplasma |
CUA | Leu | Thr | Yeast mitochondria |
AUA | Ile | Met | Human mitochondria |
AGA, AGG | Arg | Termination | Human mitochondria |
UAA, UAG | Termination | Gln | Paramecium, Tetrahymena, Stylonychia |
Chapter 14: Translation and Proteins
Overview of Translation
Translation is the process by which the genetic code carried by mRNA is decoded to produce a specific sequence of amino acids, resulting in the formation of a polypeptide chain (protein). This process requires ribosomes, tRNAs, and various protein factors.
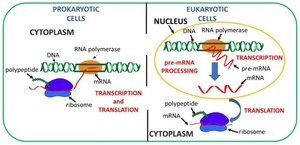
Location of Transcription and Translation
Prokaryotes: Both transcription and translation occur in the cytoplasm.
Eukaryotes: Transcription and RNA processing occur in the nucleus; translation occurs in the cytoplasm.
Ribosomes: The Site of Translation
Ribosomes are composed of ribosomal RNA (rRNA) and proteins.
They consist of large and small subunits.
Prokaryotic ribosomes are 70S; eukaryotic ribosomes are 80S (Svedberg units).
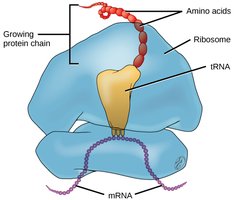
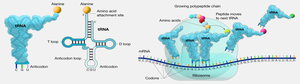
tRNA: The Adaptor Molecule
Transfer RNAs (tRNAs) are small, stable RNA molecules that serve as adaptors, matching specific amino acids to codons in the mRNA during translation. Each tRNA has an anticodon that base-pairs with the mRNA codon and an acceptor stem for amino acid attachment.
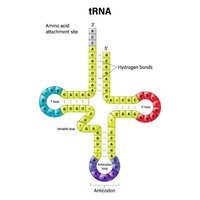
tRNA Charging and Aminoacyl-tRNA Synthetases
Before translation, tRNAs must be charged with their corresponding amino acids by enzymes called aminoacyl-tRNA synthetases.
There are 20 different synthetases, one for each amino acid, ensuring specificity.
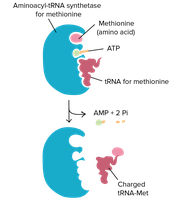
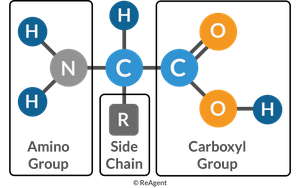
Structure of Amino Acids
Amino acids, the building blocks of proteins, have a central carbon atom bonded to an amino group, a carboxyl group, a hydrogen atom, and a variable R group (side chain) that determines the amino acid's properties.
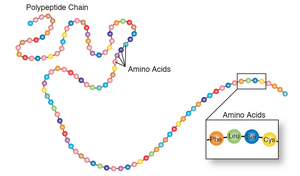
Peptide Bond Formation
Amino acids are linked by peptide bonds, formed through dehydration (condensation) reactions between the carboxyl group of one amino acid and the amino group of another. Chains of amino acids form polypeptides, which fold into functional proteins.
Steps of Translation
Initiation: The ribosome assembles on the mRNA, and the initiator tRNA binds to the start codon (AUG).
Elongation: tRNAs bring amino acids to the ribosome, where peptide bonds are formed, and the polypeptide chain grows.
Termination: When a stop codon is reached, release factors promote the release of the completed polypeptide and disassembly of the ribosome.
Translation in Eukaryotes vs. Prokaryotes
Eukaryotic translation is more complex, involving larger ribosomes, mRNA processing (5' cap, poly-A tail), and additional initiation factors.
Initiation in eukaryotes often involves the Kozak sequence, which enhances recognition of the start codon.
Translation can occur on free ribosomes or those bound to the endoplasmic reticulum.
One Gene–One Polypeptide Hypothesis
Studies of human hemoglobin established that each gene encodes a single polypeptide. Hemoglobin is a tetrameric protein composed of two alpha and two beta chains, each encoded by separate genes. Mutations in these genes can lead to disorders such as sickle-cell anemia.
Protein Structure and Diversity
Primary Structure: Sequence of amino acids in a polypeptide chain.
Secondary Structure: Local folding into alpha helices and beta sheets.
Tertiary Structure: Overall three-dimensional shape of a single polypeptide.
Quaternary Structure: Assembly of multiple polypeptide subunits.
Posttranslational Modifications
After translation, polypeptides often undergo modifications such as cleavage, phosphorylation, or glycosylation, which are essential for the protein's final structure and function.
Functions of Proteins
Proteins perform a vast array of functions, including catalysis (enzymes), structural support, transport, signaling, immune response, and regulation of gene expression. Their diversity arises from the variety of amino acid sequences and structures.
Additional info: This guide integrates foundational concepts from Chapters 13 and 14 of "Concepts of Genetics" (Twelfth Edition), focusing on the genetic code, translation, and protein structure. It is suitable for exam preparation in a college-level genetics course.
