 Back
BackThe Human Genome and Human Genetic Variation: Structure, Sequencing, and Implications 24
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
The Human Genome: Structure and Sequencing
Understanding the Human Genome
The human genome is the complete set of genetic information for Homo sapiens, encoded as DNA within the 23 pairs of chromosomes. Modern biology seeks to understand the number, function, and variation of human genes, as well as how our genome compares to other species and varies among individuals and populations.
Genome Size: Approximately 3 billion base pairs (bp).
Protein-Coding Genes: About 20,000 genes scattered across 23 chromosomes.
Key Questions: What do these genes do? How do genomes differ between individuals and populations? Do genetic differences explain disease susceptibility or behavior?
The Human Genome Project (HGP)
The Human Genome Project was an international, publicly funded effort launched in 1990 to sequence the entire human genome. It was completed in 2003, with a parallel effort by the private company Celera Genomics. The project relied on years of research using model organisms and cost approximately $3 billion.
Public vs. Private Efforts: The public project and Celera used different sequencing strategies but shared data. President Clinton declared the outcome a 'tie.'
Technological Advances: The HGP used Sanger sequencing, but newer, faster, and cheaper 'next-generation sequencing' methods have since revolutionized genomics.

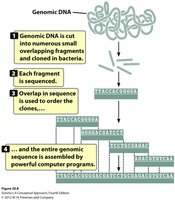
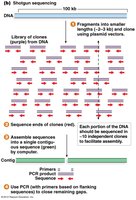
Whole Genome Shotgun Sequencing
Whole genome shotgun sequencing is a method used to determine the sequence of an organism's entire genome by breaking it into small fragments, sequencing them, and assembling the sequences computationally.
Step 1: Library Construction – The genome is digested into random fragments (~2000 bp), each cloned into a bacterial plasmid to create a 'genomic library.'
Step 2: Sequencing – Each fragment is sequenced, originally using Sanger (dideoxy) sequencing.
Step 3: Assembly – Computer algorithms identify overlapping sequences to reconstruct the original genome.
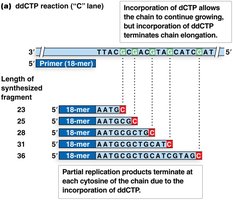
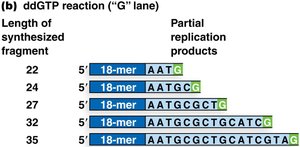
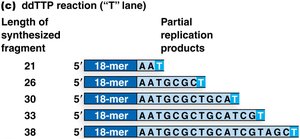
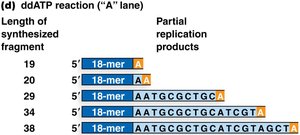
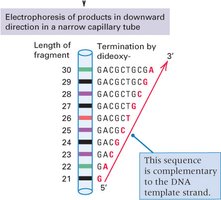
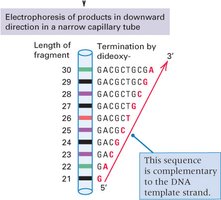
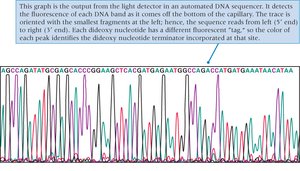
Sanger (Dideoxy) DNA Sequencing
Sanger sequencing, developed by Fred Sanger, is based on the selective incorporation of chain-terminating dideoxynucleotides (ddNTPs) during DNA replication. This method was the gold standard for DNA sequencing for decades.
Key Components: DNA template, primer, DNA polymerase, four normal dNTPs, and four fluorescently labeled ddNTPs.
Mechanism: Incorporation of a ddNTP terminates DNA synthesis at a specific base, generating fragments of varying lengths.
Detection: Fragments are separated by size using capillary electrophoresis, and the terminal base is identified by its fluorescent tag.
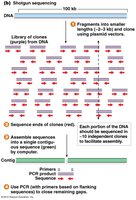
Genome Assembly
After sequencing, the short DNA fragments are assembled into longer contiguous sequences (contigs) using computational algorithms that identify overlapping regions. Gaps between contigs are filled manually or with additional sequencing.
Contigs: Overlapping fragments assembled into longer sequences.
Final Product: Ideally, one contiguous sequence per chromosome.
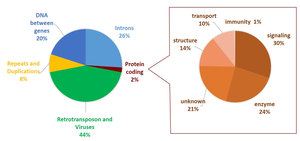
Insights from the Human Genome Sequence
Genome Composition
The human genome contains a variety of functional and non-functional elements:
Protein-Coding DNA: Only about 2% of the genome codes for proteins.
Introns and Intergenic Regions: Nearly half of the genome consists of introns and regulatory regions (promoters, enhancers).
Transposable Elements and Repeats: About 44% of the genome is made up of relics of ancient transposable elements and viruses.
Gene Number and Comparison with Other Species
Humans have approximately 20,000 protein-coding genes, a number similar to other complex animals and plants. This finding challenged earlier assumptions about human genetic complexity.

Gene Identification and Bioinformatics
Gene prediction relies on computational algorithms trained to recognize start/stop codons, open reading frames, and splice sites. The field of bioinformatics integrates computer science and biology to analyze large-scale genetic data.
GENBANK: A public database at the National Center for Biotechnology Information (NCBI) containing all available DNA sequence data.
BLAST: The Basic Local Alignment Search Tool allows researchers to compare new sequences to known genes to infer function.
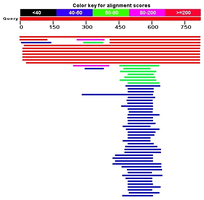
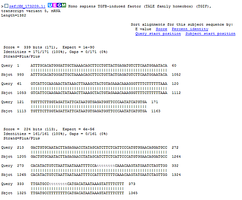
Genomic Similarity with Other Species
Humans share a high percentage of their DNA with other species, reflecting evolutionary relationships:
Neanderthal: 99%
Chimpanzee: 96%
Cat: 90%
Cow: 80%
Mouse: 75%
Fruit fly: 60%
Banana: 50%
Human Genetic Variation
Types and Sources of Variation
Genetic variation refers to differences in DNA sequences among individuals. The most common type is the single nucleotide polymorphism (SNP), but insertions, deletions, and structural variants also contribute.
Polymorphic Site: A DNA site with two or more alleles, each present in >1% of the population.
SNPs: Single base pair changes; account for 90% of human genetic variation.
Other Variants: Insertions, deletions, copy-number variants, and structural rearrangements.
Projects Studying Human Variation
Large-scale projects such as the Thousand Genomes Project have catalogued human genetic diversity across populations. A typical person's genome differs from the reference at over 4 million sites, but most variation is shared globally, supporting a common human origin.
Structural Variants: 2,100–2,500 per person.
Protein-Altering Variants: 10,000–12,000 genes per person.
Disease-Associated Variants: 25–30 per person.
Genome-Wide Association Studies (GWAS)
GWAS are used to identify genetic variants associated with diseases or traits by comparing SNPs in large groups of affected and unaffected individuals. SNP chips can analyze over 900,000 SNPs simultaneously.
Process: DNA is fragmented, labeled, and hybridized to a chip containing allele-specific probes. Fluorescent signals indicate which alleles are present.
Genotypes: Individuals can be homozygous or heterozygous at each SNP (e.g., G/G, C/C, G/C).
Interpretation: SNPs statistically associated with disease can identify individuals at increased risk, even if the SNPs do not cause the disease directly.
Applications of Human Genetic Variation
Understanding genetic variation enables:
Mapping disease genes
Predicting disease susceptibility
Forensic identification
Studying human evolution and migration
Personalized medicine (pharmacogenomics)
Pharmacogenomics
Pharmacogenomics studies how genetic variation affects drug response. For example, mutations in the CYP2D6 gene affect codeine metabolism, influencing drug efficacy and required dosage.
Direct-to-Consumer Genetic Testing
Companies offer SNP analysis or whole-genome sequencing to provide individuals with information about disease risk, ancestry, and traits. Reports may include:
Monogenic disease risk (e.g., sickle cell, Alzheimer's)
Polygenic risk scores for complex diseases
Preimplantation Genetic Diagnosis (PGD)
PGD allows for the genetic screening of embryos during in vitro fertilization. A single cell is removed from the embryo and analyzed for chromosomal abnormalities or specific genetic variants before implantation.
Summary Table: Types of Human Genetic Variation
Type of Variation | Description | Frequency |
|---|---|---|
Single Nucleotide Polymorphism (SNP) | Single base pair change | Most common; ~1 per 200 bp |
Insertion/Deletion (Indel) | Gain or loss of small DNA segments | Less common than SNPs |
Copy Number Variant (CNV) | Variation in the number of copies of a gene or region | 2,100–2,500 per person |
Structural Variant | Large-scale rearrangements (deletions, inversions, duplications) | Several thousand per person |
Key Equations and Concepts
Polygenic Risk Score: A quantitative measure of disease risk based on the sum of risk alleles across many loci.
Genotype Frequency: (Hardy-Weinberg equilibrium, where p and q are allele frequencies)
Conclusion
The sequencing of the human genome and the study of human genetic variation have transformed our understanding of biology, medicine, and evolution. Advances in sequencing technology and bioinformatics continue to drive discoveries in disease genetics, personalized medicine, and human history.
