 Back
BackThe Molecular Biology of Translation: From Genes to Proteins
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
The Genetic Basis for Protein Synthesis
Structural Genes and Their Function
Structural genes are segments of DNA that encode proteins, which are transcribed into messenger RNA (mRNA). The primary function of genetic material is to direct the production of cellular proteins in the correct cell, at the proper time, and in suitable amounts.
Structural genes: Encode proteins via mRNA transcription.
Protein synthesis: Occurs in a regulated manner to ensure proper cellular function.
Linking Genes to Proteins: Historical Perspective
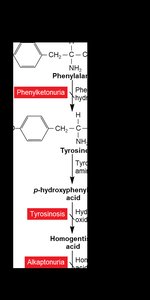
Archibald Garrod first proposed the connection between genes and proteins in the early 20th century, studying the genetic disorder alkaptonuria. He observed that patients with alkaptonuria accumulate abnormal levels of homogentisic acid, resulting in black urine and bluish-black discoloration of cartilage and skin. Garrod hypothesized that the disease was caused by a missing enzyme, homogentisic acid oxidase, and recognized it as a recessive autosomal condition.
Alkaptonuria: Caused by inheriting two defective copies of the gene encoding homogentisic acid oxidase.
Recessive inheritance: Both alleles must be defective for the disease to manifest.

Metabolic Pathways and Genetic Disorders
Metabolic pathways, such as phenylalanine metabolism, can be disrupted by genetic mutations, leading to various autosomal recessive disorders. These conditions, including phenylketonuria, tyrosinosis, and alkaptonuria, result from defects in enzymes required for the breakdown of phenylalanine.
Phenylalanine metabolism: Involves multiple enzymatic steps; disruption leads to metabolic disorders.
Autosomal recessive traits: Require two defective gene copies for disease expression.
One Gene–One Enzyme Hypothesis
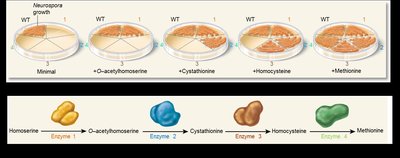
Beadle and Tatum’s Experiments
Beadle and Tatum (1940s) used bread mold (Neurospora) to demonstrate that genes encode enzymes. By identifying mutants that required specific vitamins or amino acids, they mapped enzymatic pathways and proposed the one gene–one enzyme model.
Mutant analysis: Revealed the order of enzymatic steps in metabolic pathways.
One gene–one enzyme: Each gene encodes a specific enzyme.
Modern Modifications to the Model
The one gene–one enzyme hypothesis has been refined to account for the complexity of gene expression:
Enzymes are one category of proteins: Not all proteins are enzymes.
Proteins may consist of multiple polypeptides: The term polypeptide refers to structure, while protein refers to function.
Some genes encode functional RNA: Examples include tRNA and rRNA.
Alternative splicing: One gene can encode multiple polypeptides.
The Genetic Code and Translation
Decoding the Genetic Information
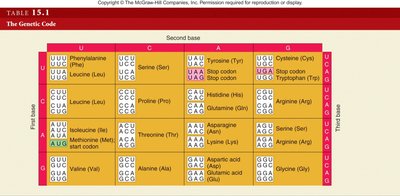
Translation is the process by which the nucleotide sequence of mRNA is interpreted into the amino acid sequence of proteins. The genetic code is organized in codons—groups of three nucleotides—each specifying an amino acid.
Codons: Triplets of nucleotides in mRNA recognized by tRNA anticodons.
Start codon: AUG (methionine) sets the reading frame.
Stop codons: UAA, UAG, UGA signal termination.
Degeneracy: Multiple codons can specify the same amino acid (wobble base).
Universality: The genetic code is nearly universal across organisms.
Polypeptide Chain Directionality
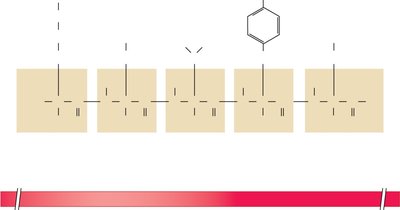
Polypeptides have directionality, with an N-terminal (amino end) and a C-terminal (carboxyl end). Peptide bonds form between the carboxyl group of one amino acid and the amino group of the next.
N-terminal: First amino acid, exposed amino group.
C-terminal: Last amino acid, exposed carboxyl group.
Amino Acids and Protein Structure
There are 20 standard amino acids, each with a unique side chain (R group). Amino acids are classified based on their properties:
Nonpolar, aliphatic: Hydrophobic, often buried inside proteins.
Aromatic: Contain ring structures.
Polar, neutral: Hydrophilic, often on protein surfaces.
Polar, acidic: Negatively charged.
Polar, basic: Positively charged.
tRNA Structure and Function
Recognition Between tRNA and mRNA
During translation, the anticodon of tRNA binds to the complementary codon in mRNA. tRNAs are named according to the amino acid they carry, and the anticodon is anti-parallel to the codon.
Anticodon-codon pairing: Ensures correct amino acid incorporation.
tRNA structure: Cloverleaf secondary structure with three stem-loops, variable regions, and an acceptor stem.
Modified nucleotides: Over 60 types, including inosine, methylinosine, ribothymidine, dihydrouridine, dimethylguanosine, and pseudouridine.
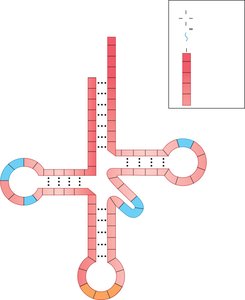
Charging of tRNAs
Aminoacyl-tRNA synthetases are enzymes that attach amino acids to their corresponding tRNAs, a process known as "charging." There are 20 synthetases, one for each amino acid, and the error rate is extremely low.
Recognition sites: Include anticodon and other tRNA sequences.
Second genetic code: Ensures high fidelity in amino acid attachment.
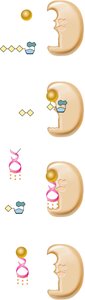
Wobble Hypothesis
The genetic code's degeneracy is explained by the wobble hypothesis, proposed by Francis Crick. The first two positions of the codon pair strictly, while the third position can "wobble," allowing certain mismatches and flexibility in tRNA recognition.
Wobble base: Usually the third base of the codon.
Inosine: A modified base that can pair with multiple nucleotides. what is the role of inosine?
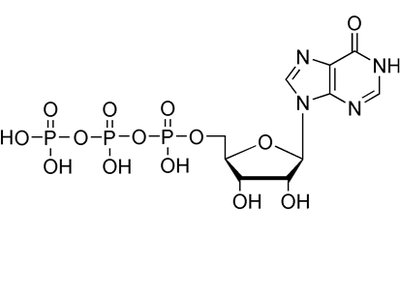
Ribosome Structure and Translation
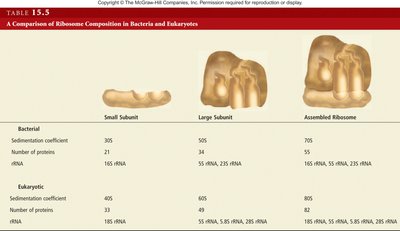
Ribosome Composition and Assembly
Ribosomes are composed of large and small subunits, each made of proteins and rRNA. Bacterial cells have a single type of ribosome, whereas eukaryotic cells have both cytoplasmic and organelle ribosomes.
Bacterial ribosome: 70S, composed of 50S (large) and 30S (small) subunits.
Eukaryotic ribosome: 80S, composed of 60S (large) and 40S (small) subunits.
Small Subunit | Large Subunit | Assembled Ribosome | |
|---|---|---|---|
Bacterial | 30S, 21 proteins, 16S rRNA | 50S, 34 proteins, 23S & 5S rRNA | 70S, 55 proteins, 16S, 23S, 5S rRNA |
Eukaryotic | 40S, 33 proteins, 18S rRNA | 60S, 49 proteins, 28S, 5.8S, 5S rRNA | 80S, 82 proteins, 18S, 28S, 5.8S, 5S rRNA |
Functional Sites of Ribosomes
Ribosomes contain three discrete sites for tRNA binding:
Aminoacyl site (A site): Entry point for charged tRNA.
Peptidyl site (P site): Holds the tRNA with the growing polypeptide chain.
Exit site (E site): Where uncharged tRNA exits the ribosome.
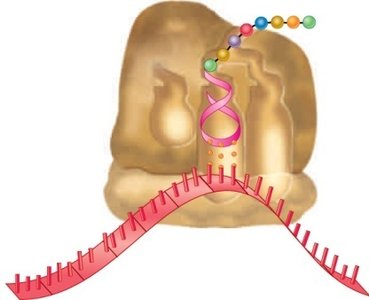
Stages of Translation
Initiation
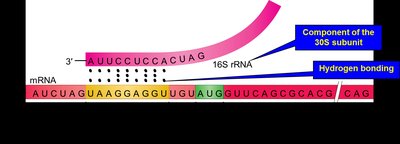
Translation initiation involves the binding of mRNA to the small ribosomal subunit, facilitated by a ribosomal-binding site (Shine-Dalgarno sequence in bacteria). The initiator tRNA (tRNAfMet in bacteria) binds to the start codon, and the large subunit joins to form the initiation complex.
Shine-Dalgarno sequence: Complementary to 16S rRNA.
Initiator tRNA: Only charged tRNA entering through the P site.
Kozak's rules: In eukaryotes, the first AUG after the 5' cap is usually the start codon.
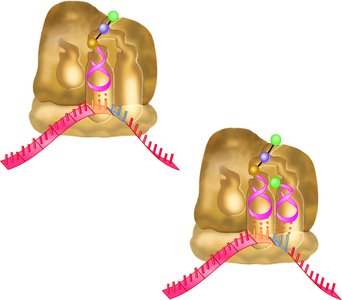
Elongation
During elongation, amino acids are added one at a time to the growing polypeptide chain. EF-Tu facilitates tRNA binding, and peptidyl transferase (a component of the 50S subunit) catalyzes peptide bond formation. The ribosome translocates one codon at a time, promoted by EF-G.
Peptidyl transferase: Ribosomal RNA acts as a ribozyme.
Decoding function: 16S rRNA ensures high fidelity in codon-anticodon recognition.
Error rate: 1 mistake per 10,000 amino acids added.
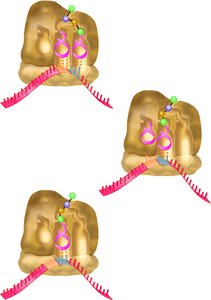
Termination
Translation terminates when a stop codon is reached. These codons are recognized by release factors, not tRNAs. The 3-D structure of release factors mimics tRNAs, facilitating the release of the completed polypeptide.
Stop codons: UAG, UAA, UGA.
Release factors: Proteins that trigger termination.
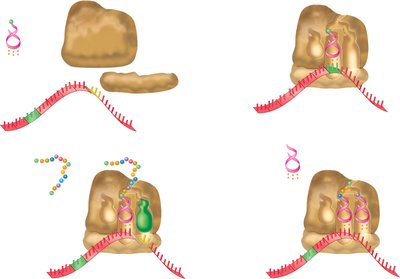
Bacterial Translation Coupling
Transcription and Translation Coupling
Bacteria lack a nucleus, so transcription and translation occur simultaneously in the cytoplasm. As soon as an mRNA strand is long enough, ribosomes attach to its 5' end, and translation begins before transcription ends. This phenomenon is called coupling, and a polyribosome (polysome) is an mRNA transcript with multiple ribosomes translating it.
Coupling: Allows rapid protein synthesis in bacteria.
Polysome: Multiple ribosomes translating a single mRNA.
 Additional info: The notes above expand on the original content with academic context, definitions, and examples to ensure completeness and clarity for genetics students.
Additional info: The notes above expand on the original content with academic context, definitions, and examples to ensure completeness and clarity for genetics students.
