 Back
BackTranslation and Post-Translational Modifications in Genetics
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Translation: Decoding the Genetic Message
Overview of Translation
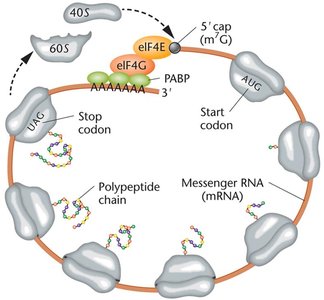
Translation is the process by which the genetic information encoded in messenger RNA (mRNA) is used to synthesize polypeptides (proteins). This process occurs in the cytoplasm and involves ribosomes, transfer RNAs (tRNAs), and various protein factors. The genetic code, composed of nucleotide triplets called codons, specifies the sequence of amino acids in a protein.
mRNA: Contains codons, each specifying an amino acid.
tRNA: Adapter molecules with anticodons complementary to mRNA codons; carry specific amino acids.
Ribosomes: Large RNA-protein complexes with large and small subunits; provide sites for mRNA binding and peptide bond formation.
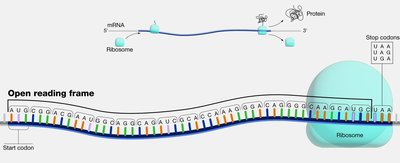
Open Reading Frame (ORF)
An open reading frame (ORF) is a continuous stretch of RNA sequence that begins with a start codon (usually AUG) and ends with a stop codon (UAA, UAG, or UGA). ORFs are the regions of mRNA that can be translated into proteins.
Start codon: Typically AUG (methionine).
Stop codons: UAA, UAG, UGA; signal termination of translation.
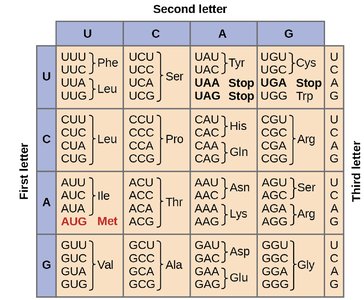
The Genetic Code and Wobble Hypothesis
The genetic code is composed of 64 possible codons (43 combinations of four nucleotides in triplets), which encode 20 amino acids. The code is degenerate, meaning that most amino acids are specified by more than one codon. The third base of the codon (the "wobble position") is often less important for determining the amino acid, allowing for some flexibility in codon-anticodon pairing.
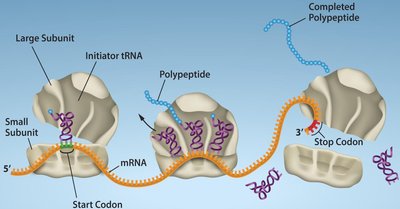
Stages of Translation
Translation occurs in three major stages: initiation, elongation, and termination. Each stage involves specific molecular factors and steps.
Initiation: Assembly of the ribosome on the mRNA and placement of the initiator tRNA at the start codon.
Elongation: Sequential addition of amino acids to the growing polypeptide chain.
Termination: Release of the completed polypeptide when a stop codon is encountered.
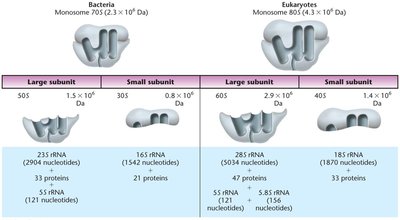
Translation in Prokaryotes vs. Eukaryotes
While the basic mechanism of translation is conserved, there are key differences between prokaryotic and eukaryotic translation.
Feature | Prokaryotes | Eukaryotes |
|---|---|---|
Ribosome Size | 70S (50S + 30S) | 80S (60S + 40S) |
Initiation Site | Shine-Dalgarno sequence | Kozak sequence |
Initiator tRNA | fMet-tRNAfMet | Met-tRNAiMet |
Location | Cytoplasm | Transcription in nucleus, translation in cytoplasm |
tRNA Structure and Function
tRNA Structure
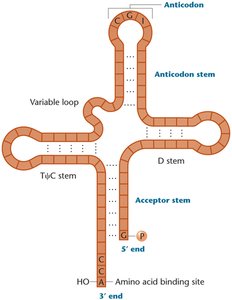
Transfer RNAs (tRNAs) are small, stable RNA molecules (75–90 nucleotides) that serve as adapters between mRNA codons and amino acids. They have a characteristic cloverleaf structure with four stems and three loops, including the anticodon loop, which base-pairs with the mRNA codon. The 3' end of the tRNA always ends with the sequence CCA, which is the attachment site for the amino acid.
Charging of tRNAs
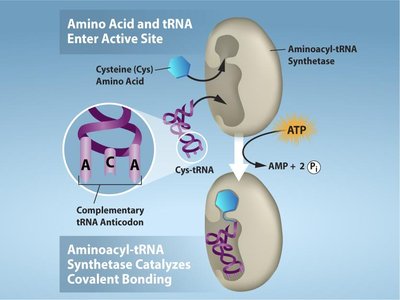
tRNAs are "charged" with their corresponding amino acids by enzymes called aminoacyl-tRNA synthetases. Each amino acid has its own specific synthetase, ensuring high fidelity in translation. The charging reaction requires ATP and results in a covalent bond between the amino acid and the tRNA.
tRNA Modifications
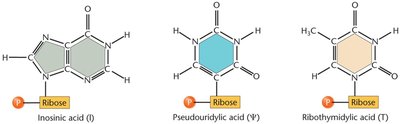
tRNAs undergo extensive post-transcriptional modifications, including base modifications, trimming of precursor sequences, addition of the CCA tail, and removal of introns. These modifications enhance tRNA stability, translation accuracy, and flexibility in codon recognition.
Ribosomal DNA (rDNA) and Ribosome Structure
rDNA Organization
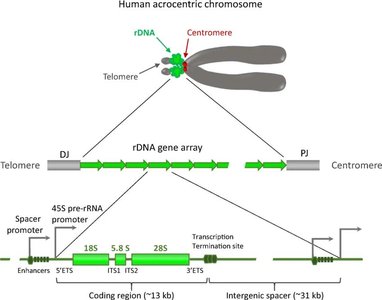
Ribosomal DNA (rDNA) refers to the DNA sequences that encode ribosomal RNA (rRNA) molecules. These genes are organized in tandem repeats and clustered at specific chromosomal regions called nucleolus organizer regions (NORs). In humans, rDNA repeats are found on the short arms of acrocentric chromosomes (13, 14, 15, 21, 22).
Ribosome Structure
Ribosomes are composed of rRNA and proteins, forming large and small subunits. Prokaryotic ribosomes are 70S (50S + 30S), while eukaryotic ribosomes are 80S (60S + 40S). The subunits provide binding sites for mRNA and tRNAs, and catalyze peptide bond formation.
Mechanism of Translation
Initiation (Prokaryotes)
In bacteria, the small ribosomal subunit binds to the Shine–Dalgarno sequence on the mRNA, positioning the start codon (AUG) in the P site. The initiator tRNA carrying N-formylmethionine (fMet) binds to the start codon. Initiation factors (IF1, IF2, IF3) assist in assembly, and the large subunit joins to form the complete ribosome.
Elongation
During elongation, aminoacyl-tRNAs enter the A site, peptide bonds are formed, and the ribosome translocates along the mRNA. Elongation factors (EF-Tu, EF-G) facilitate these steps. The process repeats, adding amino acids to the growing polypeptide chain.
Termination
When a stop codon enters the A site, release factors (RF1, RF2, RF3) recognize the codon and trigger the release of the completed polypeptide from the ribosome. The ribosomal subunits then dissociate.
Translation in Eukaryotes
Eukaryotic translation involves larger ribosomes, more initiation factors, and additional mRNA processing (5' cap, poly-A tail). The ribosome recognizes the start codon within the Kozak sequence, and translation occurs in the cytoplasm.
One-Gene–One-Enzyme and One-Gene–One-Polypeptide Hypotheses
Early experiments demonstrated that each gene encodes a specific enzyme (one-gene–one-enzyme hypothesis). This was later refined to the one-gene–one-polypeptide hypothesis, recognizing that not all proteins are enzymes and some proteins are composed of multiple polypeptide chains.
Protein Folding, Modification, and Targeting
Protein Folding
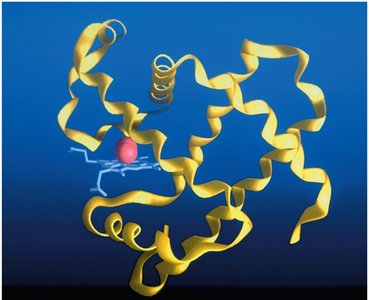
After translation, polypeptides fold into specific three-dimensional structures. Some proteins fold spontaneously, while others require chaperone proteins. Proper folding is essential for function; misfolded proteins can lead to disease.
Protein Targeting
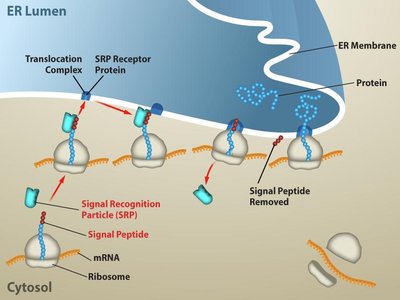
Signal sequences direct proteins to specific cellular compartments. For example, proteins destined for secretion contain an N-terminal signal sequence recognized by the signal recognition particle (SRP), targeting the ribosome to the endoplasmic reticulum (ER).
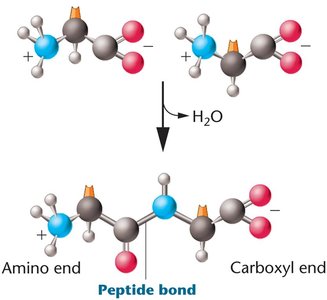
Peptide Bond Formation and Protein Structure
Peptide bonds are formed by dehydration reactions between the carboxyl group of one amino acid and the amino group of another. Proteins have four levels of structure: primary (amino acid sequence), secondary (α-helix, β-pleated sheet), tertiary (three-dimensional conformation), and quaternary (multiple polypeptide chains).
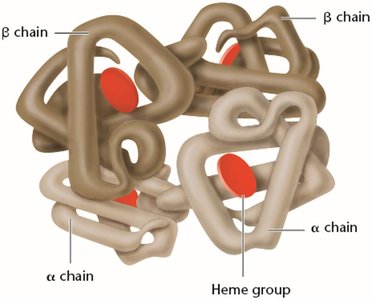
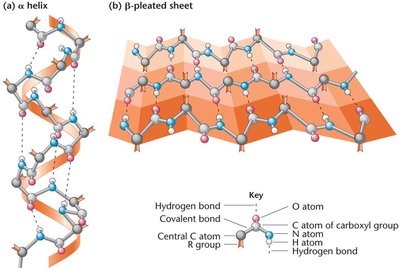
Mutations and Protein Function
Effects of Mutations
Mutations in the coding sequence of a gene can alter the amino acid sequence of the protein, potentially affecting its structure and function. For example, insertion mutations can shift the reading frame (frameshift mutation), leading to dramatic changes in the protein product.
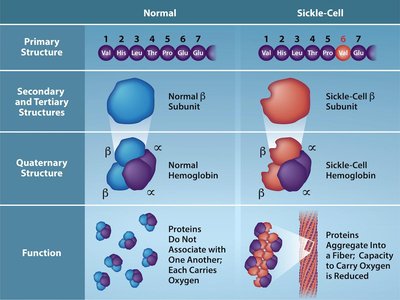
Sickle-Cell Anemia Example
Sickle-cell anemia is caused by a point mutation in the β-globin gene, changing a glutamic acid to valine. This single amino acid substitution causes hemoglobin molecules to aggregate, distorting red blood cells and impairing oxygen transport.
Post-Translational Modifications
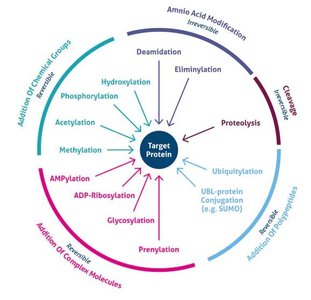
Types and Functions
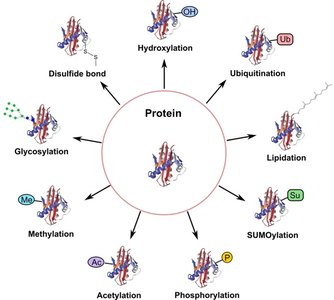
After translation, polypeptides often undergo post-translational modifications (PTMs) that are crucial for their final function. These modifications include phosphorylation, acetylation, methylation, glycosylation, ubiquitination, SUMOylation, lipidation, hydroxylation, and disulfide bond formation.
Modification | Main Function |
|---|---|
Phosphorylation | Regulates enzyme activity and cell signaling |
Acetylation | Controls gene expression and protein stability |
Methylation | Modulates protein interactions and gene regulation |
Glycosylation | Aids protein folding, stability, and cell recognition |
Ubiquitination | Tags proteins for degradation by the proteasome |
SUMOylation | Regulates protein localization and transcription |
Lipidation | Targets proteins to cell membranes |
Hydroxylation | Important for collagen stability and oxygen sensing |
Disulfide bonds | Stabilize protein structure |
Protein Domains and Functional Diversity
Protein Domains
Protein domains are distinct structural and functional units within a protein, typically 50–300 amino acids in length. Different domains confer different functional capabilities, such as DNA binding, dimerization, or ligand binding. Transcription factors, for example, are modular proteins with DNA-binding and effector domains.
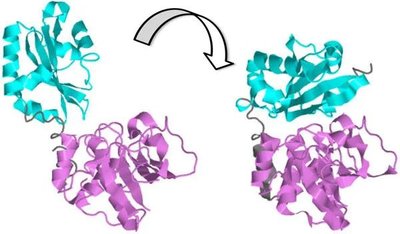
Protein-Protein Interactions
Protein-protein interactions (PPIs) are essential for many cellular processes, including signal transduction and gene regulation. PPIs can induce conformational changes that activate or inhibit protein function.
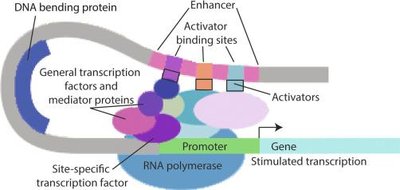
Regulation of Gene Expression
Multiple Levels of Regulation
Gene expression is regulated at multiple steps, from chromatin structure and transcription to mRNA processing, translation, and protein degradation. The final level of active protein in the cell depends on both synthesis and degradation rates.
Ubiquitination and Protein Degradation
Ubiquitination is a post-translational modification that tags proteins for degradation by the proteasome. This process is a key mechanism for controlling protein levels and regulating gene expression.
Example: NF-κB Pathway Regulation
The NF-κB signaling pathway is regulated by multiple post-translational mechanisms, including ubiquitination, phosphorylation, proteolytic cleavage, and translocation of transcription factors into the nucleus. These modifications control the activation and inactivation of inflammatory gene expression.
Additional info: The study of translation and post-translational modifications is essential for understanding how genetic information is expressed as functional proteins and how mutations or regulatory failures can lead to disease.
