 Back
BackGenomic Technologies, Sequencing, and Multi-Omics in Modern Genetics
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Recombinant DNA Technology and Genetically Modified Organisms (GMOs)
Introduction to GMOs and Recombinant DNA
Genetically Modified Organisms (GMOs) are organisms whose genetic material has been altered using recombinant DNA technology. This process involves the combination of DNA from different sources to create new genetic combinations with desired traits.
Recombinant DNA: DNA molecules formed by laboratory methods of genetic recombination to bring together genetic material from multiple sources.
GMOs: Organisms (plants, animals, or microbes) whose genomes have been engineered for research, agriculture, or medicine.
Applications: Crop improvement, pharmaceutical production, gene therapy, and research models.

DNA Sequencing Technologies
Overview of DNA Sequencing
DNA sequencing is the process of determining the precise order of nucleotides within a DNA molecule. Advances in sequencing technology have revolutionized genetics, enabling large-scale genomic studies and personalized medicine.
Goal: To determine the complete sequence of nucleotide bases (A, T, C, G) in a DNA sample.
Applications: Genome mapping, disease gene identification, evolutionary studies, and biotechnology.

Generations of DNA Sequencing
DNA sequencing technologies are classified into three generations, each with distinct methodologies and capabilities.
First Generation: Sanger sequencing – chain-termination method, low throughput, high accuracy, single gene or fragment analysis.
Second Generation: Next Generation Sequencing (NGS) – massively parallel, short reads, high throughput, cost-effective for large-scale projects.
Third Generation: Single-molecule sequencing (e.g., PacBio, Nanopore) – long reads, real-time sequencing, suitable for complex genomes and structural variation analysis.
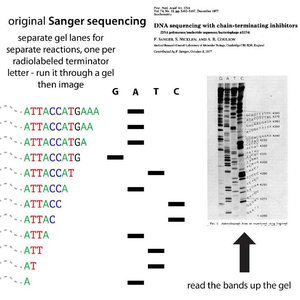

Sanger Sequencing (First Generation)
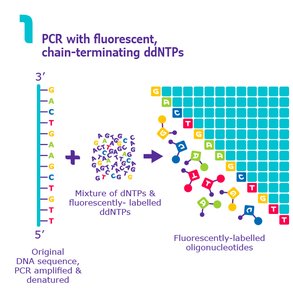
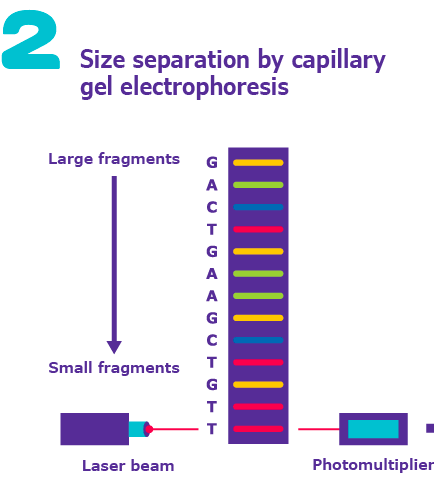
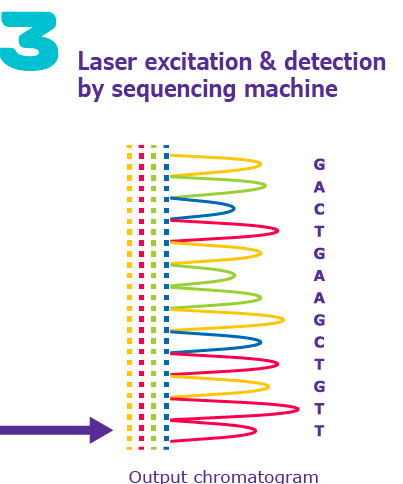
Sanger sequencing uses chain-terminating dideoxynucleotides (ddNTPs) to generate DNA fragments of varying lengths, which are then separated by electrophoresis to determine the DNA sequence.
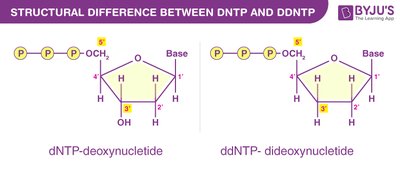
Key Principle: Incorporation of ddNTPs terminates DNA synthesis at specific bases due to the absence of a 3'-OH group.
Detection: Fragments are separated by size and detected by fluorescence or radioactivity.
Output: Sequence is read from the pattern of terminated fragments.
Next Generation Sequencing (NGS, Second Generation)
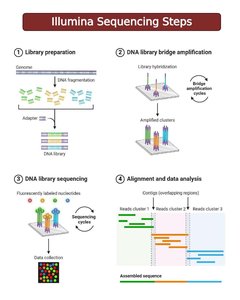
NGS technologies, such as Illumina sequencing, enable massively parallel sequencing of millions of short DNA fragments, greatly increasing throughput and reducing cost per base.
Sequencing by Synthesis: DNA fragments are amplified and sequenced in parallel, with each nucleotide addition detected by fluorescence.
Applications: Whole genome sequencing, transcriptomics, metagenomics, and more.
Advantages: High throughput, cost-effective, suitable for large-scale studies.
Third Generation Sequencing
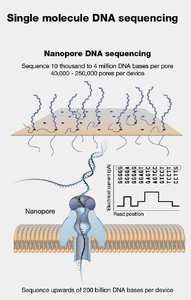
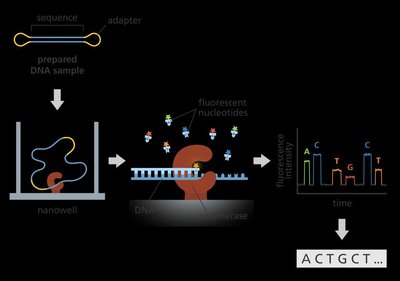
Third generation sequencing technologies, such as PacBio SMRT and Oxford Nanopore, sequence single DNA molecules in real time, producing long reads that facilitate assembly of complex genomes.
Single-Molecule Real-Time (SMRT) Sequencing: DNA polymerase synthesizes DNA in a nanowell, with real-time detection of nucleotide incorporation.
Nanopore Sequencing: DNA passes through a nanopore, and changes in electrical current are used to identify bases.
Advantages: Long read lengths, detection of epigenetic modifications, real-time data output.

Genomic Analysis and the Human Genome Project
What is Genomics?
Genomics is the study of the complete set of DNA (the genome) in an organism, including its structure, function, evolution, and mapping. It encompasses both the sequencing and functional annotation of all genetic elements.
Structural Genomics: Determining the physical structure and organization of the genome.
Functional Genomics: Assigning biological functions to genomic elements, such as genes and regulatory regions.
Human Genome Project (HGP)
The Human Genome Project was an international effort to sequence and map all human genes. It provided a reference genome for biomedical research and comparative genomics.
Timeline: Draft released in 2000, declared complete in 2003, with final gapless assembly in 2022.
Approach: Used BACs/YACs for cloning, Sanger sequencing, and later NGS for gap closure.
Outcomes: Identification of ~20,000 protein-coding genes, discovery of genetic variation (SNPs, CNVs), and insights into human evolution.

Genome Assembly and Mapping
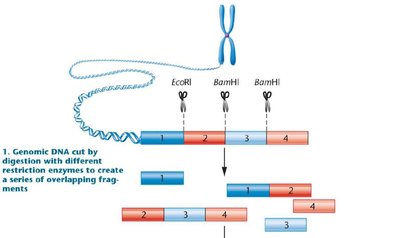
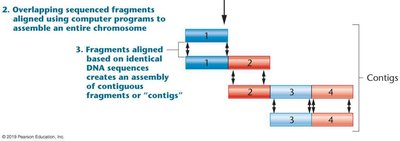
Genome assembly is the process of reconstructing the original genome sequence from short DNA fragments (reads) generated by sequencing technologies.
Contigs: Overlapping sequence reads are merged to form contiguous sequences.
Scaffolds: Contigs are ordered and oriented using additional data (e.g., genetic maps) to form larger sequences.
Genetic Mapping: Based on recombination frequencies, measured in centimorgans (cM).
Physical Mapping: Based on actual base-pair distances, using sequencing or restriction mapping.

Features of the Human Genome
Genome Size: ~3.1 billion nucleotides
Protein-Coding Genes: ~20,000 (about 2% of the genome)
Genetic Variation: SNPs (single-nucleotide polymorphisms), CNVs (copy number variations)
ENCODE Project: Catalogs functional elements, including regulatory regions and non-coding RNAs.
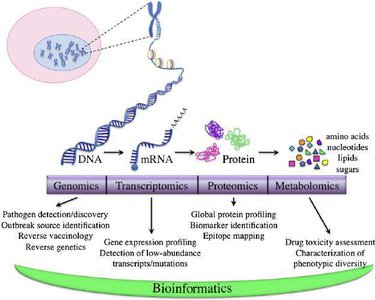
Multi-Omics Technologies
Introduction to Multi-Omics
Multi-omics refers to the integrated analysis of various 'omics' data types to provide a comprehensive view of biological systems. This approach is essential for understanding complex traits and diseases.
Genomics: Study of the complete DNA sequence.
Transcriptomics: Analysis of all expressed RNA molecules (mRNA, ncRNA).
Epigenomics: Study of DNA methylation, histone modifications, and chromatin accessibility.
Proteomics: Analysis of the entire set of proteins.
Metabolomics: Study of metabolites and small molecules in cells.
Transcriptomics
Transcriptomics involves the global analysis of gene expression, identifying which genes are expressed and at what levels in specific tissues or conditions.
RNA Sequencing (RNA-seq): Uses NGS to quantify and compare gene expression.
Applications: Cancer diagnostics, developmental biology, disease research.
Bulk vs. Single-Cell RNA-seq: Bulk provides average expression; single-cell reveals cell-type-specific expression and heterogeneity.
Epigenomics
Epigenomics studies heritable changes in gene expression that do not involve changes to the underlying DNA sequence, such as DNA methylation and histone modification.
Methods: Whole genome bisulfite sequencing (WGBS), ATAC-seq, ChIP-seq.
Applications: Cancer research, developmental biology, environmental studies.
Proteomics
Proteomics is the large-scale study of proteins, including their expression, structure, and function. It is essential for understanding cellular processes and disease mechanisms.
Techniques: LC-MS/MS (liquid chromatography-tandem mass spectrometry), Western blotting, ELISA.
Applications: Biomarker discovery, drug development, disease diagnostics.
Metagenomics
Metagenomics involves sequencing the collective genomes of microbial communities from environmental samples, providing insights into microbial diversity and function.
Applications: Environmental monitoring, human microbiome studies, discovery of novel genes and pathways.
Comparative and Functional Genomics
Comparative Genomics
Comparative genomics analyzes and compares genome sequences from different species to identify conserved and unique genetic elements, understand evolutionary relationships, and discover genes responsible for specific traits or diseases.
Applications: Evolutionary biology, disease gene identification, functional annotation.
Functional Genomics
Functional genomics aims to understand the roles and interactions of genes and other genomic elements, often using high-throughput techniques such as microarrays and RNA-seq.
Goals: Predict gene function, analyze gene expression, and study regulatory networks.
Summary Table: DNA Sequencing Technologies
Generation | Technology | Read Length | Throughput | Key Features |
|---|---|---|---|---|
First | Sanger Sequencing | 500-1,000 bp | Low | High accuracy, single gene, chain-termination |
Second | Illumina (NGS) | 50-500 bp | High | Massively parallel, short reads, cost-effective |
Third | PACBIO, Nanopore | 10,000+ bp | Very High | Long reads, real-time, single molecule |
