Textbook Question
Finding the Mean of a Frequency Distribution In Exercises 49–52, approximate the mean of the frequency distribution.
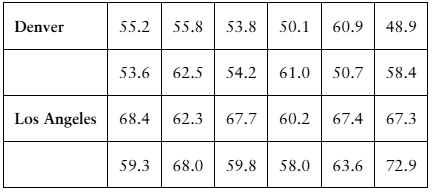
Social Media The average daily amounts of time (in minutes) spent on Snapchat
267
views

 Verified step by step guidance
Verified step by step guidance
 06:14
06:14 08:45
08:45 04:52
04:52Finding the Mean of a Frequency Distribution In Exercises 49–52, approximate the mean of the frequency distribution.
Social Media The average daily amounts of time (in minutes) spent on Snapchat
Finding z-Scores The distribution of the ages of the winners of the Tour de France from 1903 to 2020 is approximately bell-shaped. The mean age is 27.9 years, with a standard deviation of 3.4 years. In Exercises 43–48, use the corresponding z-score to determine whether the age is unusual. Explain your reasoning. (Source: Le Tour de France)
Finding a Weighted Mean In Exercises 41– 46, find the weighted mean of the data.
Grades A student receives the grades shown below, with an A worth 4 points, a B worth 3 points, a C worth 2 points, and a D worth 1 point. What is the student’s grade point average?
Finding the Mean of a Frequency Distribution In Exercises 49–52, approximate the mean of the frequency distribution.
Populations The populations (in thousands) of the counties in Montana in 2019 (Source: U.S. Census Bureau)
Constructing a Frequency Distribution and a Frequency Polygon In Exercises 35 and 36, construct a frequency distribution and a frequency polygon for the data set using the indicated number of classes. Describe any patterns.
Declaration of Independence
Number of classes: 5
Data set: Number of children of those who signed the Declaration of Independence (Source: The U.S. National Archives & Records Administration) 5 2 12 18 7 4 10 8 16 3 3 7 3 1 2 7 13 0 8 3 7 5 2 6 0 6 7 9 0 11 9 10 7 8 13 5 8 3 5 0 3 13 3 15 5 6 3 2 5 2 0 3 7 12 4 1
Graphical Analysis In Exercises 19–22, use the box-and-whisker plot to determine whether the shape of the distribution represented is symmetric, skewed left, skewed right, or none of these. Justify your answer.