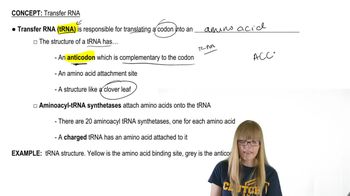
Textbook Question
A portion of the coding strand of DNA for a gene has the sequence
5′-...GGAGAGAATGAATCT...-3′
Write out the template DNA strand sequence and polarity as well as the mRNA sequence and polarity for this gene segment.
924
views

 Verified step by step guidance
Verified step by step guidance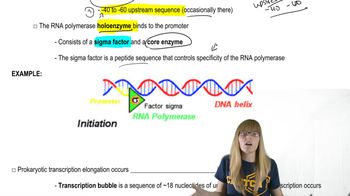
 10:14
10:14 07:58
07:58A portion of the coding strand of DNA for a gene has the sequence
5′-...GGAGAGAATGAATCT...-3′
Write out the template DNA strand sequence and polarity as well as the mRNA sequence and polarity for this gene segment.
A portion of the coding strand of DNA for a gene has the sequence
5′-...GGAGAGAATGAATCT...-3′
Assuming the mRNA is in the correct reading frame, write the amino acid sequence of the polypeptide using three-letter abbreviations and, separately, the amino acid sequence using one-letter abbreviations.
A eukaryotic mRNA has the following sequence. The 5' cap is indicated in italics (CAP), and the 3' poly(A) tail is indicated by italicized adenines.
5′-CAPCCAAGCGUUACAUGUAUGGAGAGAAUGAAACUGAGGCUUGCCACGUUUGUUAAGCACCUAUGCUACCGAAAAAAAAAAAAAAAAAAAAAAAA-3′
Locate the start codon and stop codon in this sequence.
Diagram a eukaryotic gene containing three exons and two introns, the pre-mRNA and mature mRNA transcript of the gene, and a partial polypeptide that contains the following sequences and features. Carefully align the nucleic acids, and locate each sequence or feature on the appropriate molecule.
a. The AG and GU dinucleotides corresponding to intron-exon junctions
b. The +1 nucleotide
c. The 5' UTR and the 3' UTR
d. The start codon sequence
e. A stop codon sequence
f. A codon sequence for the amino acids Gly-His-Arg at the end of exon 1 and a codon sequence for the amino acids Leu-Trp-Ala at the beginning of exon 2
Table C contains DNA-sequence information compiled by Marilyn Kozak (1987). The data consist of the percentage of A, C, G, and T at each position among the 12 nucleotides preceding the start codon in 699 genes from various vertebrate species and at the first nucleotide after the start codon. (The start codon occupies positions +1 to +3 and the first nucleotide immediately after the start codon occupies position +4) Use the data to determine the consensus sequence for the 13 nucleotides ( -12 to -1 and +4) surrounding the start codon in vertebrate genes.
Table D lists α-globin and β-globin gene sequences for the 11 or 12 nucleotides preceding the start codon and the first nucleotide following the start codon (see Problem 34). The data are for 16 vertebrate globin genes reported by Kozak (1987). The sequences are written from -12 to +4 with the start codon sequence in capital letters. Use the data in this table to:
Determine the consensus sequence for the 16 selected α-globin and β-globin genes.