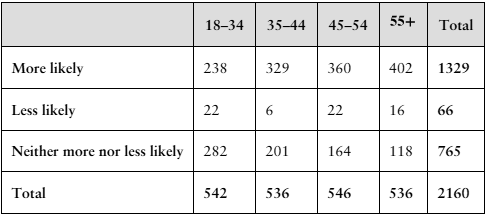
Multiple Choice
Which sampling method involves dividing the population into groups () and then taking a random sample from each group?
22
views
 Verified step by step guidanceVerified video answer for a similar problem:
Verified step by step guidanceVerified video answer for a similar problem:
 08:18
08:18 07:09
07:09 06:38
06:38 5:37m
5:37mMaster Introduction to Probability with a bite sized video explanation from Patrick
Start learning