


 06:14
06:14

Textbook Question
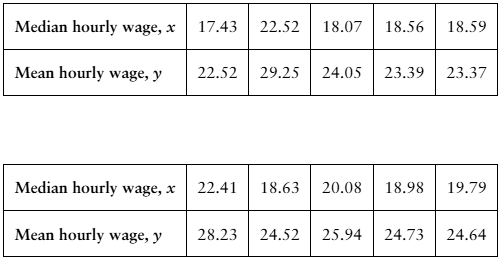
"Finding the Coefficient of Determination and the Standard Error of Estimate In Exercises 11-20, use the data to (a) find the coefficient of determination r^2 and interpret the result,
12. [APPLET] Median and Mean Hourly Wages The table shows the median and mean hourly wages (in dollars) in 10 states in a recent year. The equation of the regression line is y = 1.208x + 1.495. (Source: U.S. Census Bureau)
"
163
views