Multiple Choice
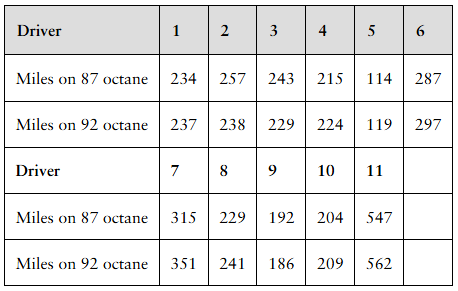
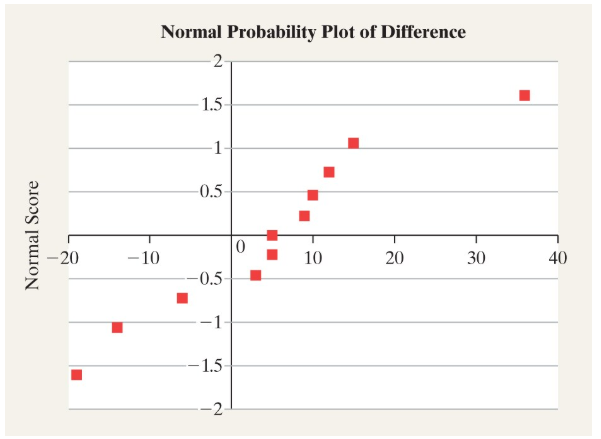
Which of the following is an example of a dependent sample suitable for analysis with the -test?
41
views
 Verified step by step guidanceVerified video answer for a similar problem:
Verified step by step guidanceVerified video answer for a similar problem:
 08:33
08:33 07:23
07:23 05:43
05:43 8:33m
8:33mMaster Introduction to Matched Pairs with a bite sized video explanation from Patrick
Start learning