

 08:45
08:45

Textbook Question
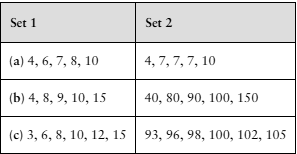
Birth Weights Babies born after a gestation period of 32–35 weeks have a mean weight of 2600 grams and a standard deviation of 660 grams. Babies born after a gestation period of 40 weeks have a mean weight of 3500 grams and a standard deviation of 470 grams. Suppose a 34-week gestation period baby weighs 3000 grams and a 40-week gestation period baby weighs 3900 grams. What is the z-score for the 34-week gestation period baby? What is the z-score for the 40-week gestation period baby? Which baby weighs less relative to the gestation period?
68
views