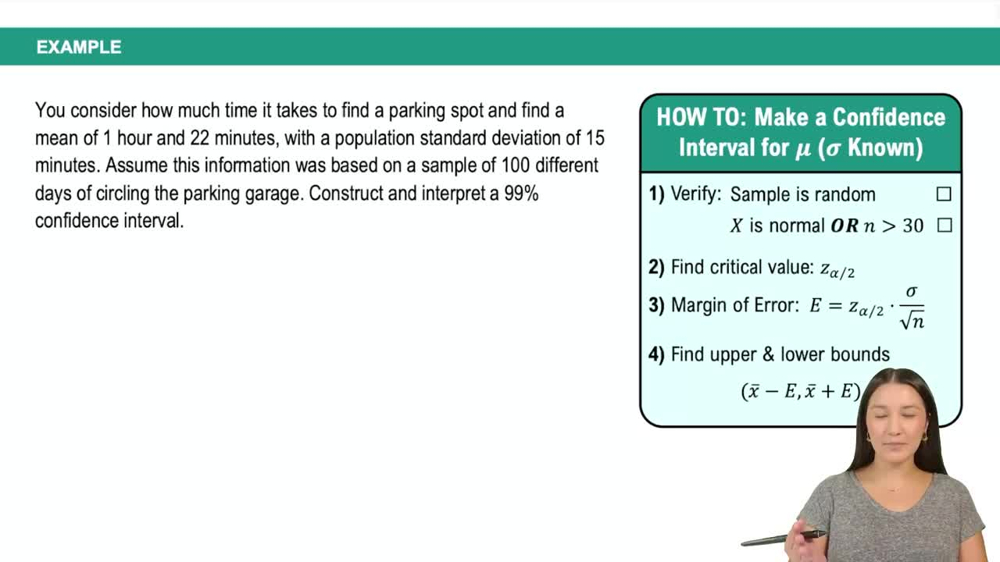
If the consequences of making a Type I error are severe, would you choose the level of significance, α, to equal 0.01, 0.05, or 0.10? Why?
Verified step by step guidance
1
Understand that the level of significance, \( \alpha \), represents the probability of making a Type I error, which is rejecting the null hypothesis when it is actually true.
Recognize that if the consequences of making a Type I error are severe, we want to minimize the chance of making this error.
Since \( \alpha \) controls the probability of a Type I error, choosing a smaller \( \alpha \) reduces this risk.
Compare the given options: \( \alpha = 0.01 \), \( 0.05 \), and \( 0.10 \). The smallest value, \( 0.01 \), corresponds to the lowest probability of a Type I error.
Therefore, to minimize the risk of a severe Type I error, you would choose \( \alpha = 0.01 \).
Verified video answer for a similar problem:
This video solution was recommended by our tutors as helpful for the problem above
Video duration:
5m
Play a video:
0 Comments
Key Concepts
Here are the essential concepts you must grasp in order to answer the question correctly.
Type I Error
A Type I error occurs when a true null hypothesis is incorrectly rejected, meaning we conclude there is an effect when there isn't one. It is also called a false positive, and its probability is denoted by the significance level α.
The level of significance, α, is the threshold probability for rejecting the null hypothesis. It represents the maximum acceptable risk of making a Type I error, commonly set at 0.01, 0.05, or 0.10 depending on the context.
Finding Binomial Probabilities Using TI-84 Example 1
Trade-off Between Type I and Type II Errors
Choosing a smaller α reduces the chance of a Type I error but increases the risk of a Type II error (failing to reject a false null). When Type I errors have severe consequences, a lower α (e.g., 0.01) is preferred to minimize false positives.

 Verified step by step guidance
Verified step by step guidance
 04:24
04:24